
故事是这样的。
RAG这个词,我大概在一年多前就开始频繁地在各种技术群、公众号、推特上刷到了。每次看到有人聊RAG,我都会本能地点进去看两眼,然后。。。看不到三分之一就退出来了。
不是因为看不懂,而是每次看到的内容都是那种很"教科书"的拆解,向量数据库、embedding、chunk、retrieval,一堆英文术语堆在一起,看完之后我脑子里只剩下一个模糊的印象,"哦,就是让AI去查资料然后再回答"。
对吗?好像对。但又感觉没那么简单。
直到最近这段时间,我自己在工作中真的遇到了一些场景,让我不得不认真坐下来搞明白这个东西到底是怎么回事。所以今天这篇文章,就是我花了一整天时间研究之后的理解,尽量用大白话聊透它。
如果你跟我一样,之前对RAG只停留在"听说过"但从没认真了解过的阶段,那这篇应该能帮到你。
先说一个我觉得还挺重要的前提认知。
我们现在用的这些大语言模型,不管是ChatGPT还是Claude还是Gemini,它们其实都有一个很致命的问题,它们的知识是有"截止日期"的。就像一个人,大学毕业之后如果再也不看书不看新闻,他的知识就永远停在毕业那天。
大模型也一样。它们在训练的时候吃了海量的数据,但训练完成之后,除非重新训练,否则它对世界的认知就定格了。你问它2026年6月发生了什么事,它大概率答不上来或者瞎编一个出来。
这就是所谓的"幻觉"问题。模型不知道答案,但它又不甘心说"我不知道",于是就煞有介事地编一个听起来很像那么回事的答案出来。
你想想看,如果你是一家企业,你想让AI帮你的客服回答用户问题,但AI压根不知道你们公司的产品手册里写了什么,它要么答不出来,要么就按照它自己的理解瞎说。这搁谁谁受得了?
RAG就是为了解决这个问题而生的。
RAG的全称是Retrieval-Augmented Generation,翻译过来就是"检索增强生成"。我自己的理解是这样的,你可以把它想象成一个学生在开卷考试。
普通的大模型像什么呢?像一个记忆力超强但有点自负的学生,在闭卷考试。他脑子里存了大量知识,大部分时候能答对,但遇到他没见过的题目,他宁可编一个答案也不愿意空着。
而RAG呢,就是让这个学生可以翻书。考试的时候,他先看看题目问的是什么,然后翻到相关的那几页,读一遍,再结合自己的理解组织答案。
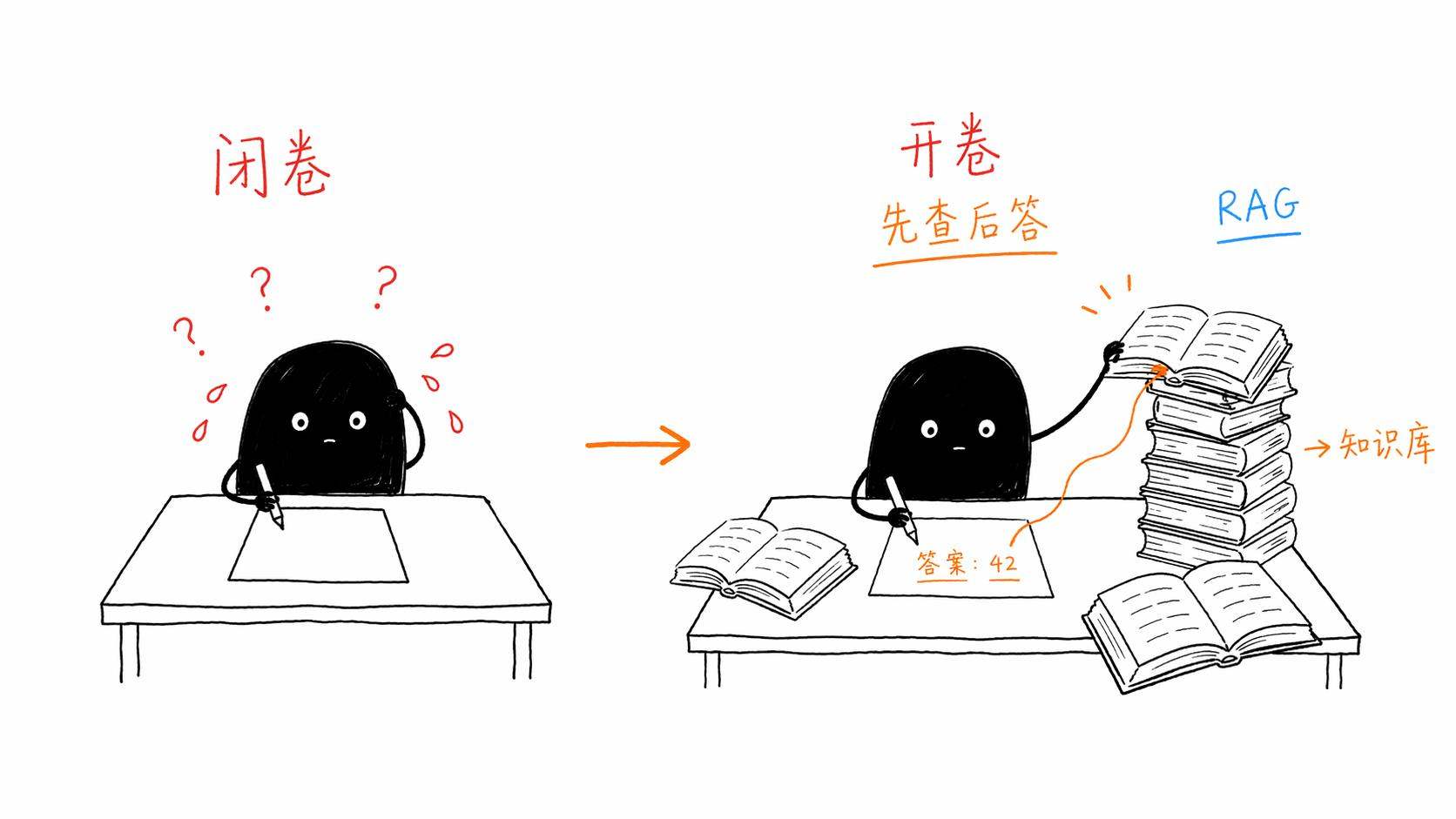
这个"翻书"的动作,就是RAG里的R,Retrieval,检索。
翻完书之后用自己的话回答问题,就是G,Generation,生成。
中间那个A,Augmented,增强,说的是"检索到的内容增强了生成的质量"。
所以整个RAG的核心逻辑其实超级简单,用一句话概括就是,先查后答。
当然了,真正做起来远没有这四个字听着那么轻松。这里面有很多细节值得展开聊。
回到"查"这个动作本身。
模型要查什么?查的是你提前准备好的一个"知识库"。这个知识库可以是你们公司的产品文档、FAQ、操作手册、技术规范,也可以是法律条文、医学指南、论文集,whatever,反正就是你希望AI能够基于这些内容来回答问题。
但问题来了,这些文档可能有几百万字,你不可能整个塞给模型。一来模型的上下文窗口有限制(虽然现在Claude能吃200k token,Gemini甚至能吃2M,但成本和效率都是问题),二来就算全塞进去,模型也容易"迷失在中间",找不到重点。
所以RAG的做法是,把这些文档切成小块,然后在用户提问的时候,只把最相关的那几块找出来,塞给模型。
这个过程大概分三步。
第一步,预处理。把你的文档切成一块一块的(业内叫chunking,分块),每一块大概几百字到一两千字不等。然后用一个叫embedding model的东西,把每一块文字转成一个数学向量。你可以把向量理解成一组坐标,语义相近的文字,转出来的坐标也会很接近。这些向量存到一个专门的数据库里,叫向量数据库,比如Pinecone、Milvus、Chroma这些。
第二步,检索。当用户问了一个问题,系统先把这个问题也转成向量,然后去向量数据库里找"离这个问题最近的那几块文档"。就像在一个图书馆里,你告诉管理员"我想了解MaxSavers账户的取款限额",管理员就去书架上把跟这个话题最相关的三五页内容抽出来递给你。
第三步,生成。把用户的原始问题和检索出来的那几块文档一起打包,喂给大模型,让它基于这些内容生成答案。
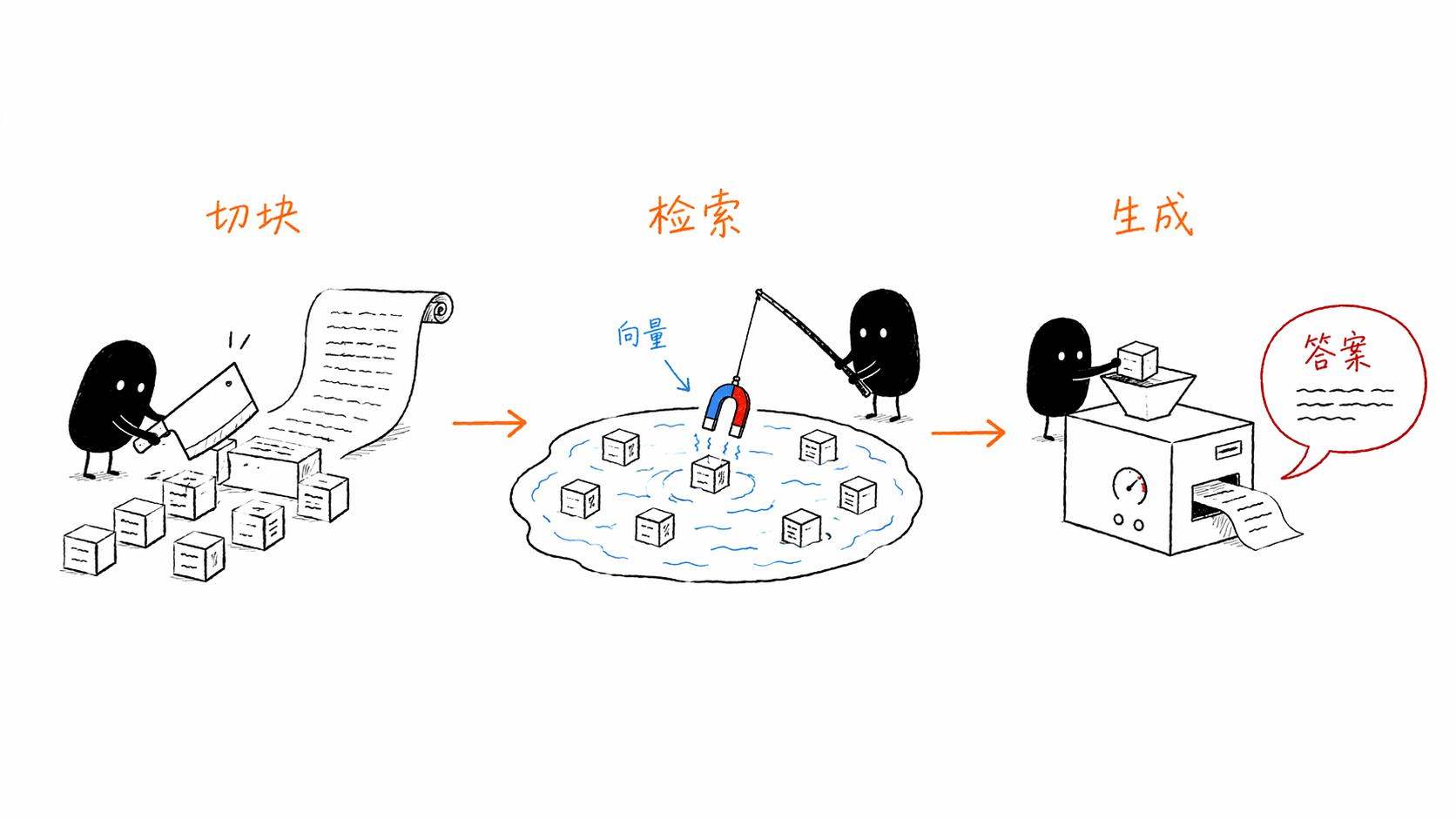
就这么简单?就这么简单。
但。。。"简单"和"做好"之间隔着一个太平洋。
我在研究过程中发现,RAG这个领域在2024到2025这两年发展得特别快,已经从最初那个朴素的"查一下再答"进化出了一大堆花活。让我挑几个我觉得最有意思的说。
第一个,分块策略。
前面说了要把文档切成小块,但怎么切其实是个大学问。最笨的方法就是每500个字切一刀,不管你这500字是正好讲完一个话题还是把一句话切成两半。这种方法简单粗暴,但效果经常很烂,因为被切断的上下文信息就丢失了。
现在比较先进的做法是"语义分块",根据内容的语义来决定从哪里切。同一个话题的内容放在一块里,不同话题之间才切开。还有一种叫"智能体分块",直接让大模型自己来决定应该在哪里切,因为模型本身就能理解文本的逻辑结构。
第二个,混合检索。
纯用向量搜索有时候会翻车。比如用户的问题里有一个很具体的专有名词或者产品编号,向量搜索可能理解了大概意思但错过了这个关键词。所以现在很多系统会同时用两种搜索,向量搜索(理解语义)加关键词搜索(精确匹配),然后把两边的结果综合排序。这就像你同时用百度搜索和问一个懂行的朋友,两个渠道互补。
第三个,重排序。
初步检索出来的结果可能有十几二十条,但不是每一条都跟问题真正相关。这时候会用一个更精细(但也更慢)的模型再过一遍,把真正最相关的那三五条挑出来。这一步的作用类似于你在google搜出来一堆结果之后,用眼睛快速扫一遍标题和摘要,只点开最靠谱的那几条去看。
第四个,也是我觉得最有意思的,自我纠正。
你想想看,如果检索出来的内容本身就不靠谱怎么办?比如知识库里有些信息是过时的、矛盾的、或者跟问题压根不相关的。早期的RAG是"检索到什么就用什么",有点像一个学生翻到什么就抄什么,不管对不对。
现在有一类叫Self-RAG和Corrective RAG的技术,核心思路是让模型在生成答案之前,先"审视"一下检索到的内容,这个信息靠谱吗?跟问题相关吗?有没有互相矛盾的地方?如果发现不对劲,系统可以决定重新检索、换一个关键词再搜一次,甚至直接说"我现有的资料无法回答这个问题"。
这就相当于那个学生不仅会翻书,还学会了批判性思考。
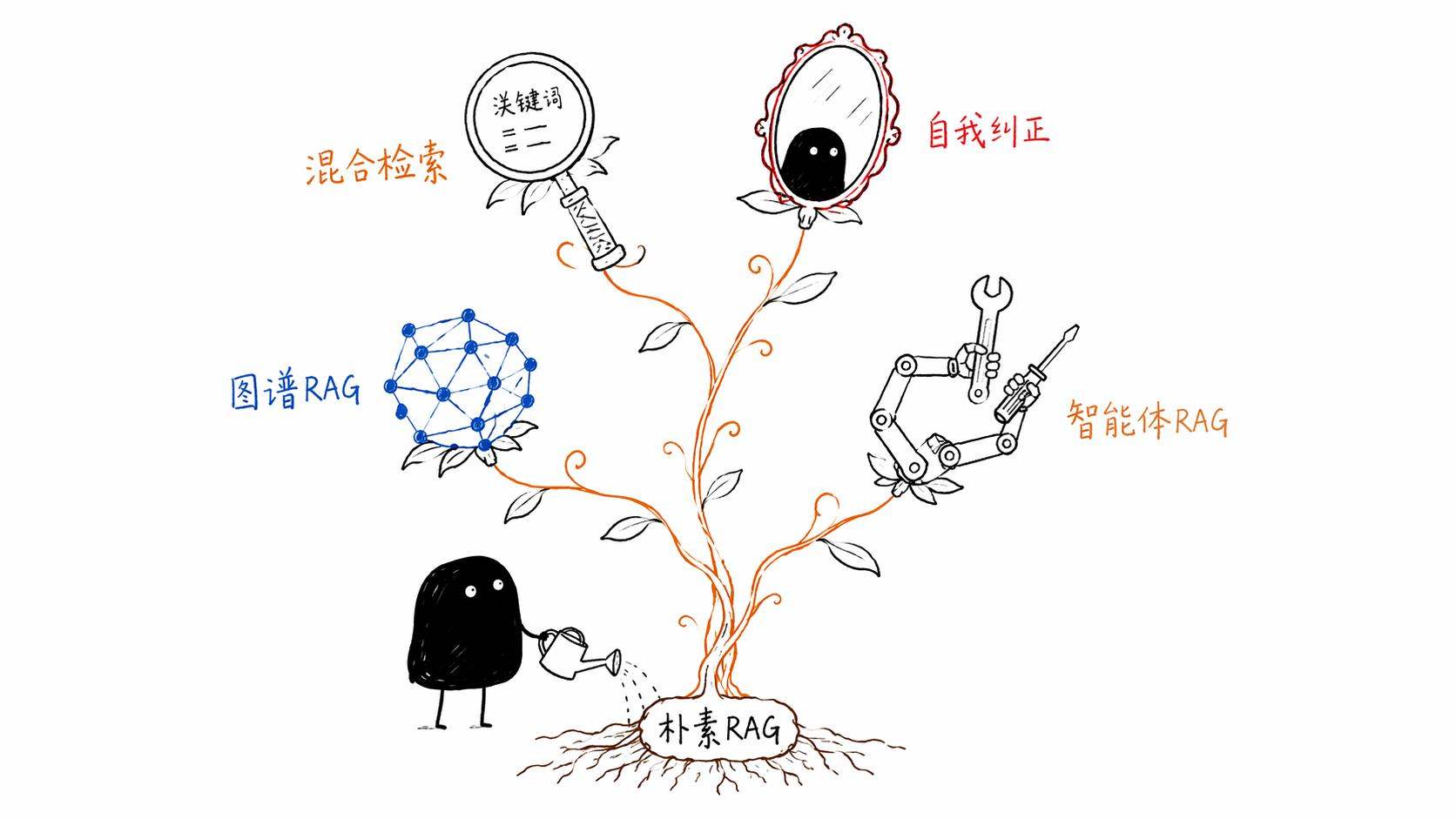
我觉得还是挺重要的。
说完技术原理,聊聊到底在什么场景下该用RAG。
坦率的讲,不是所有场景都需要RAG。如果你只是想让AI帮你写个周报、翻译一段文字、或者头脑风暴一些idea,这些任务不需要RAG,模型自身的能力就够了。
RAG真正发光的场景,是"你需要AI基于特定的、最新的、私有的信息来回答问题"。
几个典型的例子。
企业客服。你的客服机器人需要回答"我的XXX套餐还剩多少流量""你们这个产品支不支持MacOS"这种问题。这些答案都在你的产品文档和用户数据里,不在大模型的训练数据里。不上RAG,AI就只能瞎猜。
法律和金融。律师需要从几千份判例里找到跟当前案件最相关的先例,金融分析师需要从海量研报里提取关键数据。这些专业领域的知识更新快、专业性强,纯靠模型的训练数据远远不够。
内部知识管理。公司内部有几千篇wiki、几百个confluence文档、散落在各种飞书文档和slack频道里的知识。新员工入职想问"我们的发版流程是什么",与其让他翻三天文档,不如让一个RAG系统帮他秒级定位到答案。
代码仓库问答。程序员面对一个几百万行代码的项目,想了解某个模块的设计思路或者某个API的用法,让RAG去检索代码注释和设计文档,比自己一个个文件翻要高效得多。
顺着上面的再聊聊,RAG和微调(Fine-tuning)到底该怎么选?
这俩经常被拿来对比,因为它们看上去都是"让模型变得更懂某个领域"。但其实完全不是一回事。
微调是改造模型本身。 相当于让这个学生重新上了一门课,把新知识刻到了他的脑子里。好处是之后用起来很快,不用临时翻书。坏处是"上课"这个过程成本很高(需要大量标注数据和计算资源),而且如果知识更新了,你得重新再上一次课。
RAG是给模型配了一个外挂图书馆。 模型本身没变,但它可以随时去图书馆查。好处是知识更新很简单(往图书馆里加新书就行),成本也低。坏处是每次回答都要走一遍"查→读→答"的流程,会慢一点,而且检索质量直接影响回答质量。
在实际业务里,很多团队是两个都用。先用微调让模型更懂你的行业语言和表达风格,再用RAG让它能访问最新最全的具体信息。
说到这里我突然想到一个事儿。
2025年底的AWS re:Invent大会上有一个session的标题挺有意思,叫「RAG is Dead: Long Live Intelligent Retrieval-Augmented Generation」。RAG死了,智能RAG万岁。
这个标题其实很精确地概括了这个领域目前的状态。朴素的RAG确实快过时了。 那种"切块→存向量→查最近的→塞给模型"的一条线流程,在面对真正复杂的业务问题时已经不够用了。
取而代之的是一类叫Agentic RAG的东西。简单说就是,不再是一个固定流程走到底,而是有一个AI Agent来"指挥"整个RAG过程。它会根据问题的复杂度决定要不要检索、检索几轮、从哪里检索、要不要换个角度重新查一次。就像一个经验丰富的研究员,面对一个复杂问题,他不会只查一本书就下结论,他会查多个来源、交叉验证、追问细节、在不确定的时候承认不确定。
还有一类叫GraphRAG的东西也很火。传统RAG是把文档切成一块块独立的碎片去搜索,但有些知识天然是有关联的。比如"张三是A公司的CEO"和"A公司收购了B公司"这两条信息,只有把它们关联起来你才能推断出"张三现在间接管理B公司的业务"。GraphRAG就是用知识图谱把这些实体和关系串起来,让检索可以沿着关系链去追溯。
我自己的感受是,RAG这个领域现在有点像2015年前后的深度学习,底层的idea已经被验证了,接下来就是各种架构创新和工程优化的爆发期。每隔一两个月就会冒出来一个新的论文、一个新的框架、一个新的best practice。
但不管上面这些多花哨,我觉得有一个底层认知是不变的。
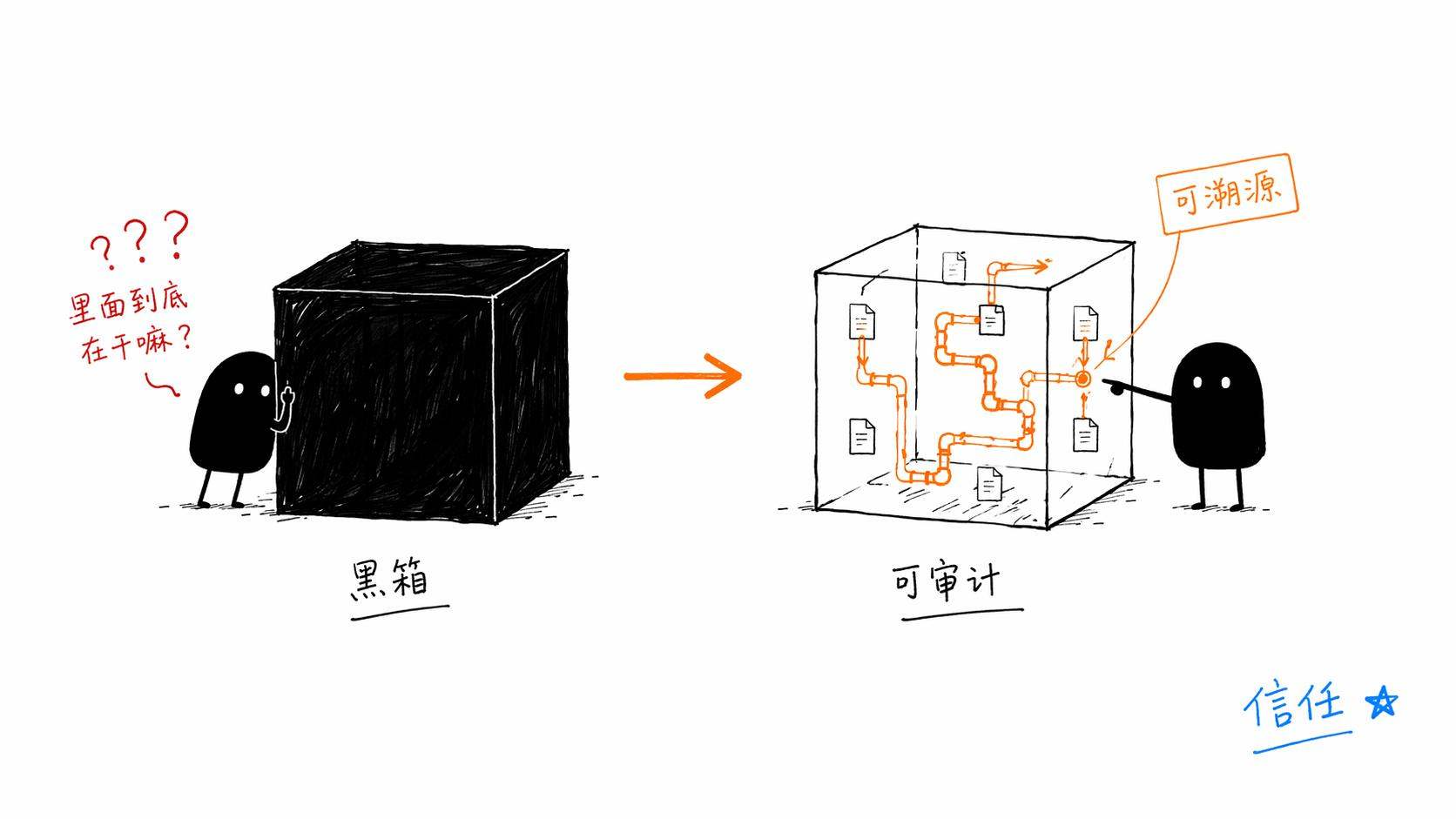
RAG的核心价值,不是让AI"更聪明",而是让AI"更诚实"。
它解决的不是智力问题,而是知识问题。让模型基于真实的、可溯源的信息来回答,而不是凭自己的"想象"编造答案。在企业场景里,这种"有据可查"的特性才是真正的杀手锏。因为你可以追溯AI的答案是基于哪条文档生成的,如果答案有误,你可以定位到是检索出了问题还是文档本身有错。
这让AI从一个"不可控的黑箱"变成了一个"可审计的工具"。我觉得这才是RAG被企业界疯狂追捧的根本原因。
写到这里差不多了。
怎么说呢,这个技术本身不难理解,就是"先查后答"四个字。但要把它做好、做到生产级别能用,中间的坑实在是太多了。分块策略怎么选、embedding模型怎么挑、检索出来的内容怎么排序怎么过滤、上下文窗口怎么分配、幻觉怎么检测。。。每一个环节都能展开写一整篇文章。
我始终坚信,对于大多数想要在业务中落地AI的团队来说,RAG是性价比最高的第一步。 不需要从头训练模型,不需要天价的GPU集群,你只需要把你的业务知识整理好、切好、存好,然后接上一个大模型,就能在很多场景下产生立竿见影的效果。
当然了,立竿见影的效果和"真正好用"之间还有很长的路要走。但至少,方向是清晰的。
永远对世界保持好奇。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
延伸阅读
- Embedding,AI世界的隐形地基:之前一直知道embedding这个概念但没深入了解过,这次认真研究了一下。从one-hot编码的致命缺陷到Word2Vec的惊人发现,从当前主流模型选型到五大应用场景,用大白话聊透向量嵌入这个AI世界的底层基建。
- 如何判断一个AI产品是不是在忽悠你:AI行业色素水浓度有点高。四层鉴伪框架教你识别:看技术在哪里、看有没有护城河、看它怎么说话、看它敢不敢让你试。知识不是用来炫耀的,是用来防身的。
- Prompt Engineering,用自然语言给AI编程的技术:Prompt Engineering不是那些满天飞的万能模板,而是一种用自然语言给AI编程的能力。五个核心原则、Context Engineering的进化、以及为什么你说话的方式决定了AI能帮你到什么程度。
- AI Agent,当AI学会自己搞定一整件事:AI Agent是Fine-tuning、Function Calling、MCP三大技术的集大成者。这篇文章从聊天机器人和Agent的本质区别讲起,拆解Agentic Loop的工作机制,坦诚讨论复合错误率的现实挑战,最终回答一个问题:当AI学会独立完成任务,什么能力变得更重要了?
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。