前面三篇文章,我分别聊了Fine-tuning、Function Calling和MCP。
写完MCP那篇的时候我就在想,其实这三个东西单独拿出来看,每一个都只是一块积木。Fine-tuning让AI有了专业能力,Function Calling让AI能动手干活,MCP让AI能连接到任何工具和数据源。但积木本身不是目的,把它们拼起来才是。
那拼起来是什么?
AI Agent。
2025到2026年,这个词大概是整个AI行业出现频率最高的术语了。每一个大厂都在做Agent,每一个创业公司都在说自己是Agent,每一个投资人都在找Agent的项目。Gartner预测到2026年底,40%的企业应用会嵌入AI Agent,而2025年这个数字还不到5%。
但你有没有发现一个很诡异的事情?满世界都在说Agent,但如果你随便拉一个人问「AI Agent到底是什么」,大概率你会得到五花八门的答案。有人说就是ChatGPT加了几个工具,有人说是一个能自己干活的AI,有人说是多个AI在一起协作,还有人说就是自动化脚本套了个壳。
所以今天这篇文章,我想把这个事情一次性讲清楚。
AI Agent和聊天机器人到底有什么区别?
这个问题是理解Agent的起点。
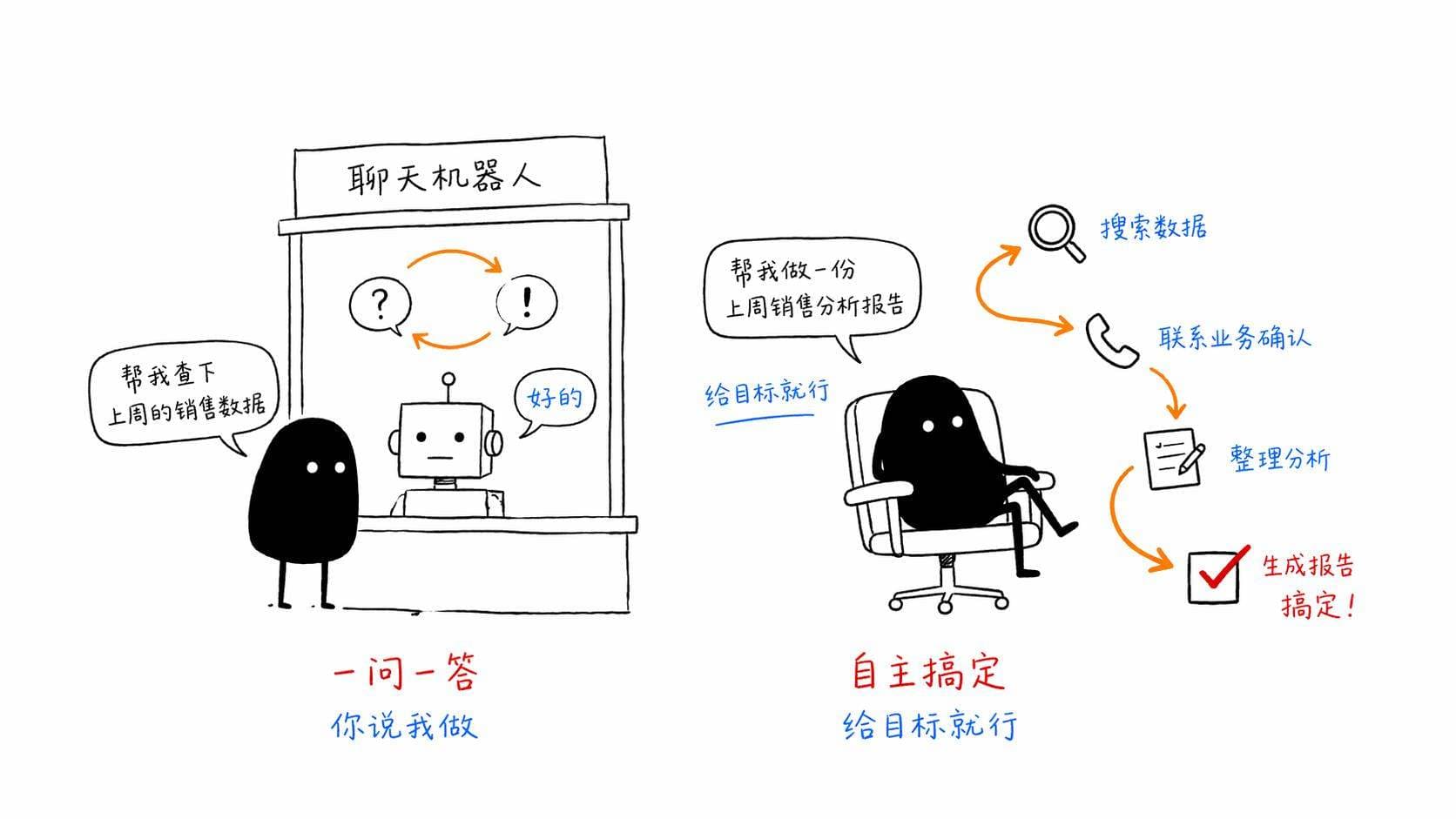
你跟ChatGPT聊天,它做的事情其实很简单,你问一句,它答一句。不管它的回答多聪明、多详细,它的工作模式始终是「一问一答」。你不问,它不动。你问了,它答完就停。
就像你去餐厅点菜,服务员站在那里等你说话,你说「来一份宫保鸡丁」,他记下来转身走了。你不说话,他就一直站着等。
这是聊天机器人。
AI Agent不一样。Agent是你说「帮我安排一顿明天的商务晚餐」,然后它自己去做这一整件事。 它会先想,商务晚餐需要什么?需要一个安静的、档次不错的餐厅。然后它去查附近有哪些合适的餐厅,看评分、看位置、看有没有包间。然后它查你明天的日程,看什么时间段有空。然后它去订位。如果订不上,它会自己换一家试试。整个过程它可能调用了六七个工具,做了十几次决策,中间还根据各种中间结果调整了方案。而你只说了一句话。
你看出区别了吗?
聊天机器人是「你问我答」。Agent是「你给目标,我去搞定」。
一个是有问必答的百科全书,一个是能替你干活的助手。
核心差异就一个词,自主性。
Agent能够自己规划步骤、自己决定用什么工具、自己判断中间结果对不对、自己决定下一步该做什么。它不是等你一步一步指挥,它是拿到一个目标之后自己跑完整个流程。
这也是为什么前面三篇文章讲的那些技术对Agent来说缺一不可。你想想看,一个Agent要能独立完成任务,它至少需要什么?
第一,它得够聪明,能理解复杂的任务并把它拆解成可执行的步骤。 这靠模型本身的推理能力,Fine-tuning可以让它在特定领域更强。
第二,它得有手,能实际执行操作。 查数据、发邮件、调API、操作系统,这些全靠Function Calling。
第三,它得能连接到各种工具和数据源。 不是只能用三五个内置工具,而是能接入任何系统。这靠MCP。
三者缺一不可。少了推理能力,它拆不了任务。少了工具调用,它有想法但动不了手。少了标准连接,它能动手但触及范围有限。
Fine-tuning是大脑,Function Calling是双手,MCP是神经网络。三者合一,才是一个完整的Agent。
说到这里,我想具体聊一下Agent到底是怎么工作的。因为很多人一听「自主完成任务」,就觉得很玄乎,好像是某种黑科技。其实不是,它的工作机制非常清晰,业内有一个专门的术语来描述这个过程。
Agentic Loop,智能体循环。
这个概念我在Function Calling那篇提过一嘴,但没有展开。今天来把它讲透。
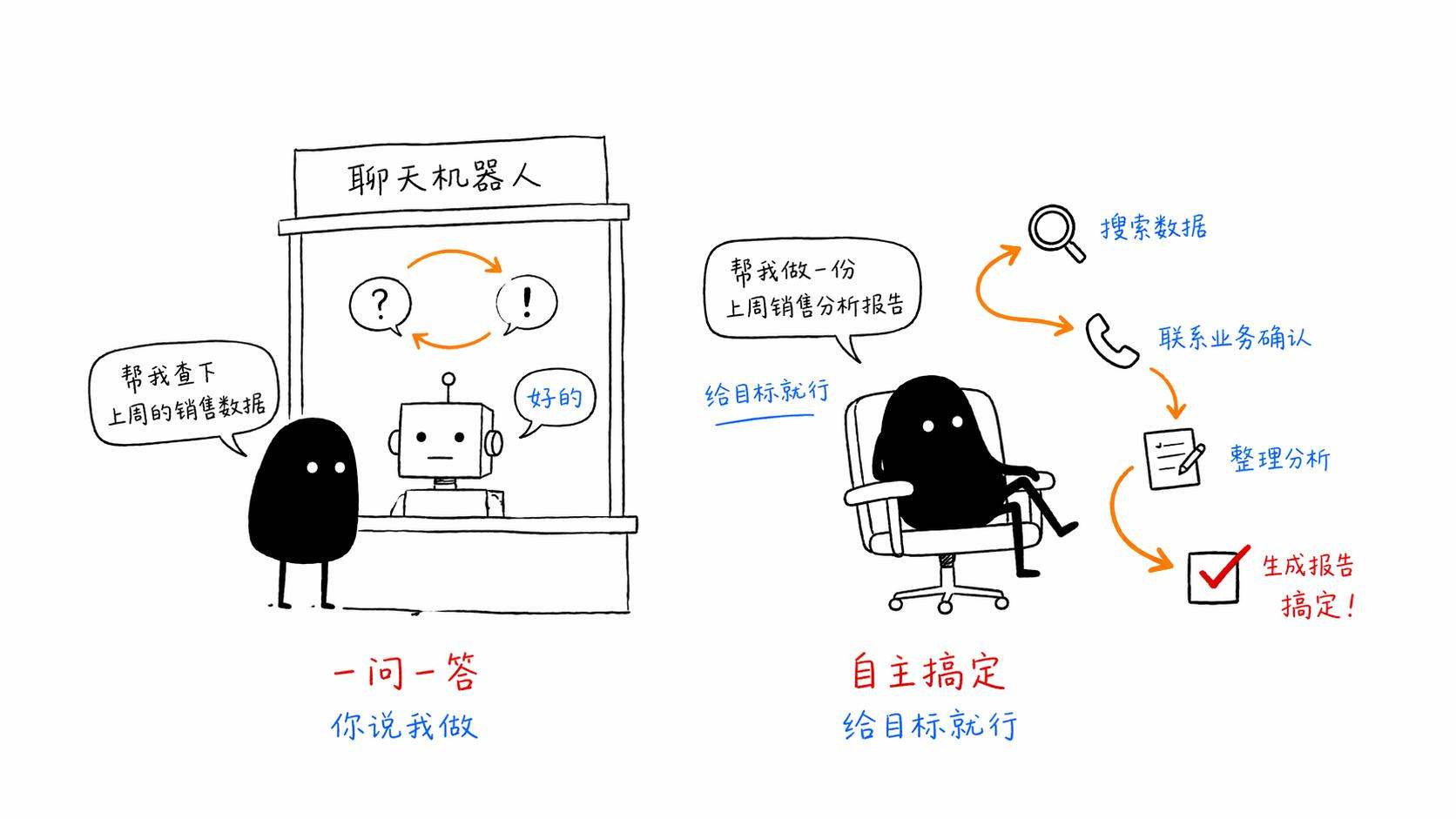
一个Agent拿到任务之后,它做的事情说到底就是不断重复四个步骤,感知→思考→行动→观察。
感知,就是接收信息。用户给了什么任务,当前的环境是什么状态,之前的操作返回了什么结果。
思考,就是推理和规划。基于当前掌握的所有信息,下一步应该做什么?需要调用什么工具?参数是什么?
行动,就是执行。调用工具、发送请求、操作系统。
观察,就是看结果。工具返回了什么?成功了吗?结果符合预期吗?需要调整方案吗?
然后,基于观察的结果,再次进入下一轮循环。感知新的状态→思考下一步→行动→观察。
这个循环一直转下去,直到任务完成或者Agent判断自己搞不定需要求助人类。
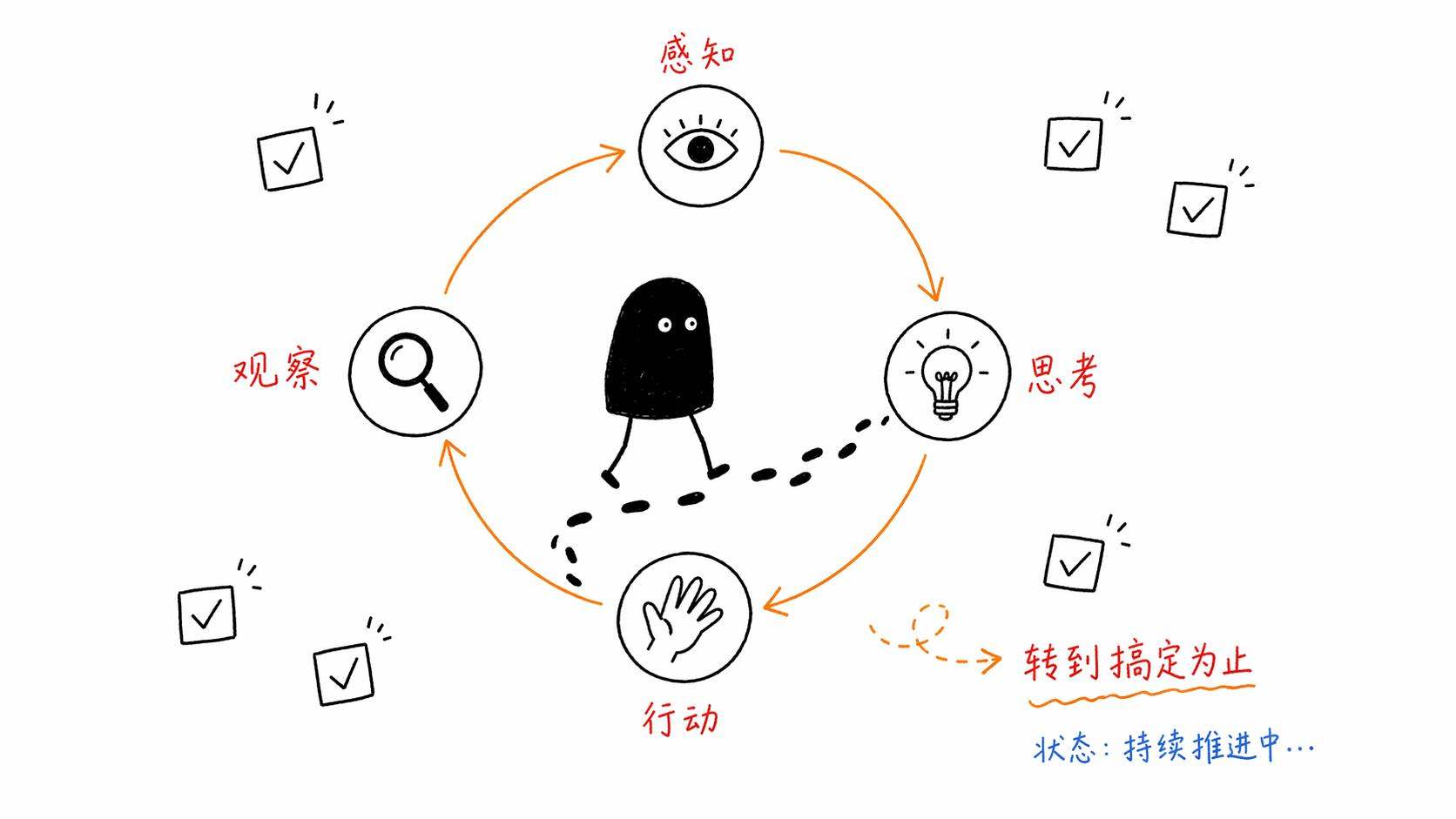
我跟你说,你去看现在市面上所有的Agent产品,不管它包装得多花哨、名字起得多玄乎,底层全是这个循环。Claude Code是这样,Cursor是这样,Devin是这样,Manus是这样,OpenAI的Operator也是这样。
区别只在于,这个循环转得有多快、有多准、能处理多复杂的任务、出错了能不能自己修复。
举一个具体的例子。
你用Claude Code让它「重构这个项目里所有的数据库查询方法,从callback风格改成async/await」。它拿到这个任务之后会怎么做?
第一轮循环,它先读你的项目结构,搞清楚有哪些文件。
第二轮循环,它逐个文件扫描,找到所有用callback风格的数据库查询。
第三轮循环,它开始改第一个文件,把callback改成async/await。
第四轮循环,它跑测试,看改完之后有没有报错。
第五轮循环,发现一个测试挂了,分析错误原因,发现少改了一个地方。
第六轮循环,修复遗漏,再跑一遍测试。通过了。
然后继续下一个文件。。。
你看,它不是「一次性把所有文件改完完事」,而是改一个、验证一个、有问题就修、修完再继续。就像一个真正在干活的程序员,不可能写完一千行代码才第一次跑测试,都是写一点测一点,出了问题当场解决。
这种「想一步做一步看一步」的工作方式,就是Agent跟传统自动化最根本的区别。
传统自动化是什么?是你预先定义好了123456每一步该做什么,然后按顺序执行。中间出了任何意外,整个流程就挂了。
Agent不一样。它没有预定义的固定步骤,它是实时根据情况做判断的。遇到意外,它会自己想办法绕过去或者换一条路。
坦率的讲,Anthropic在2024年底发过一篇非常经典的博客,叫「Building Effective Agents」。那篇文章把Agent的架构模式分成了五种,Prompt Chaining、Routing、Parallelization、Orchestrator-Workers、Evaluator-Optimizer。我自己觉得它是目前业内关于Agent架构写得最清晰的一篇东西。
但你不用记这些术语。你只需要记住一件事,所有Agent的核心都是那个循环,区别只在于循环内部的编排方式不同。 简单的Agent就是一个循环直线跑到底,复杂的Agent是多个循环嵌套在一起、并行地跑、互相协调。
说到这里,可能有人会问,如果Agent这么好,为什么现在还没有完全替代人类干活?
好问题。
因为Agent现在还不够靠谱。
我是真的觉得这件事需要说清楚。2025年到2026年,整个行业都在疯狂推Agent的概念,各种产品发布会上的demo看着都很炸裂。但你实际去用的时候就会发现,Agent在处理简单明确的任务时表现很好,一旦任务变复杂、变模糊、涉及多步骤决策,它出错的概率会显著上升。
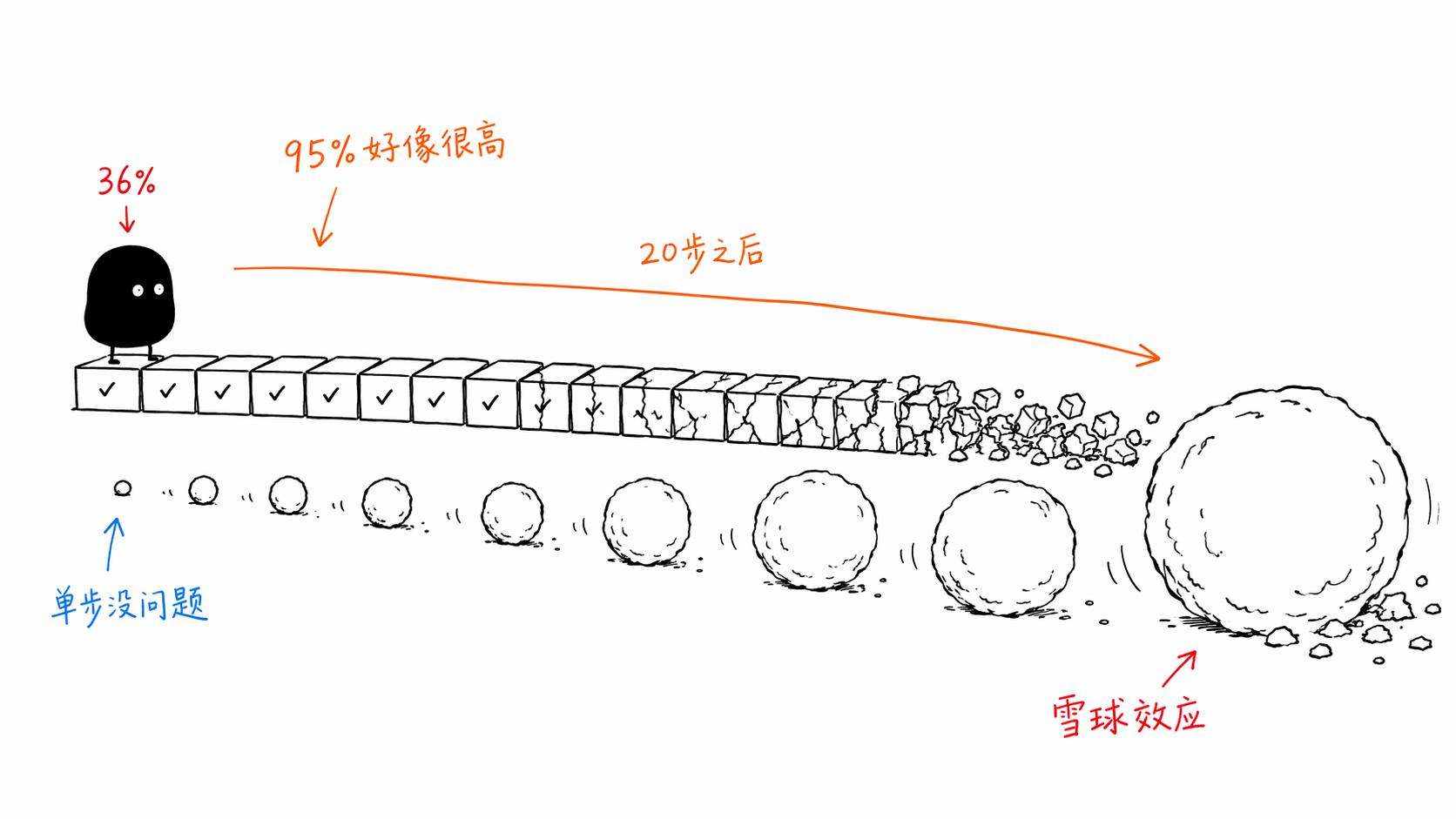
这背后有一个很简单的数学问题。
假设Agent每一步操作的成功率是95%,听起来很高对吧?但如果一个任务需要20步才能完成,那整体成功率就是0.95的20次方,大概是36%。也就是说,将近三分之二的情况下,它在某一步会出错。
如果每一步成功率是90%呢?20步下来,整体成功率只有12%。
这就是所谓的「复合错误率」问题。 单步能力再强,多步串起来之后,错误就会像滚雪球一样累积。
2025年有一篇争议很大的论文叫「Hallucination Stations」,试图从数学上证明基于Transformer的语言模型在复杂Agent任务上有根本性的局限。这个结论可能太极端了,但它指出的核心问题是真实的,当前的Agent在长链条任务上确实不够可靠。
Reddit上有个叫r/AgenticFails的社区,专门收集AI Agent翻车的案例。里面有人吐槽说Agent花了5美元的API调用费最后告诉他「我不知道答案」,有人说Agent在第三步犯了个错然后接下来十步都在错误的基础上继续建设,越错越离谱。
这不是个别案例。这是Agent目前的真实状态。
但,这也不是说Agent没用。恰恰相反,我觉得关键在于你怎么用它。
我自己的经验是,Agent现在最好用的场景,是那种「每一步都可以验证」的任务。比如写代码,写完可以跑测试,测试过了就说明这一步对了。比如数据分析,查完数据可以对一下数字对不对。比如文件处理,处理完可以检查格式对不对。
为什么?因为「可验证」意味着Agent在每一步都能自我纠错。它在第三步发现结果不对,可以回头重做第三步,而不是在错误的基础上继续往前跑。
Agent + 验证机制 = 靠谱。Agent - 验证机制 = 赌博。
这也是为什么2026年最成功的Agent产品几乎都跟代码相关。Claude Code、Cursor、Devin、Codex,这些coding agent能做到很高的完成度,核心原因不是它们的模型比别人强多少,而是代码天然有一个完美的验证机制,编译器和测试套件。模型改了代码跑不通?没关系,报错信息一出来,它自己就知道哪里有问题,修完再跑,直到通过。
反过来,那些没有明确验证机制的场景,比如「帮我写一封得体的商务邮件」「帮我做一个好看的PPT」,Agent就很难做到真正靠谱。因为什么叫「得体」什么叫「好看」,没有一个自动化的判断标准,模型只能靠自己的判断,而它的判断不一定跟你的标准一致。
聊到这里,我想把视角拉远一点,说一个我自己对Agent未来的看法。
我觉得2026年的Agent,大概处在1995年互联网的位置。
1995年的互联网是什么状态?所有人都知道这玩意是未来,但它慢、丑、不好用、动不动就断线。你用拨号上网看个网页等半天,邮件发出去不知道对方能不能收到。但所有明眼人都看得出来,这个东西一旦基础设施建好了、速度上去了、生态丰富了,它会改变一切。
Agent现在就是这个状态。它不够稳定、不够可靠、经常犯蠢。但底层的能力模型已经到了一个临界点,推理能力在飞速提升,工具调用已经标准化了(MCP),多模态交互正在成熟(Claude Computer Use、OpenAI Operator可以直接操作电脑界面)。
坦率的讲,每隔三四个月我就觉得Agent的能力跳了一个台阶。2025年初的Agent还在为10步任务挣扎,2026年中的Agent已经能比较稳定地处理30-50步的任务了。按这个速度,我觉得再过一两年,很多现在需要人盯着的工作流,Agent就能独立搞定了。
但这也引出了一个我一直在想的问题。
当Agent真的能独立完成大部分任务的时候,什么能力变得更重要了?
我自己的答案是,拆解问题和定义目标的能力。
你想想看,如果Agent的能力边界是「给它一个清晰的目标和必要的约束条件,它能自己搞定」。那瓶颈就不再是执行层面的事情了。瓶颈在于,你能不能把一个模糊的需求拆解成足够清晰的子目标?你能不能准确地告诉Agent「做到什么标准算完成」?你能不能在它跑偏的时候及时发现并纠正方向?
这跟管理团队其实是一回事。一个好的管理者不是什么事都自己干,而是能把任务拆好、把标准说清楚、把边界定明白,然后让团队去执行。
未来跟AI协作的核心能力,就是这种「定义问题」的能力。
好了,最后收个尾。
这个系列从Fine-tuning写到Agent,四篇文章下来,其实讲的是同一个故事。
AI从一个只会聊天的语言模型,一步一步变成了一个能独立完成复杂任务的智能体。Fine-tuning给了它专业身份,Function Calling给了它行动能力,MCP给了它连接万物的接口,Agent把这些全部整合在一起,形成了一个「感知→思考→行动→观察」的完整闭环。
我在MCP那篇文章结尾用了一个盖房子的比喻。Fine-tuning是地基,Function Calling是水电,MCP是市政管网。那Agent是什么?
Agent就是住在这栋房子里的那个人。
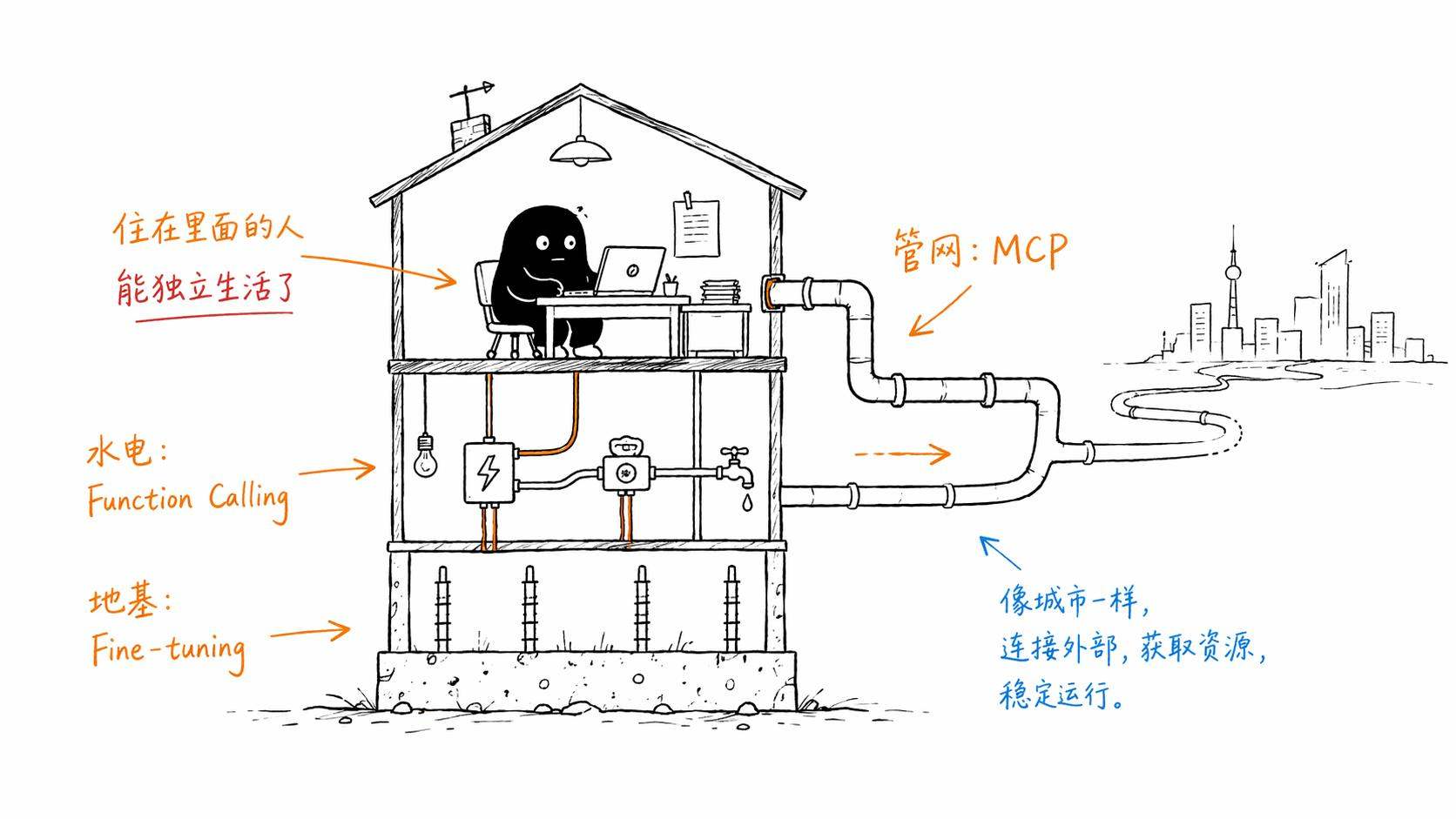
地基、水电、管网都是为了让这个人能好好生活。同样的,Fine-tuning、Function Calling、MCP这些技术,最终都是为了让Agent能好好工作。技术是手段,Agent能替人干活才是目的。
我自己回看这整个系列,觉得有一个贯穿的底层认知是这样的。AI不是一项技术,它是一个技术栈。就像你盖一栋能住人的房子,不是掌握一门手艺就行了,你需要地基工程、水电工程、装修设计、城市规划。。。每一层解决一个具体的问题,叠在一起才能构成一个真正好用的系统。
如果你是一个想在实际业务中用好AI的人,我的建议是,别只盯着某一层技术看。 要理解整个栈是怎么配合的,然后根据你自己的业务场景,判断你需要在哪一层发力。有些场景只需要一个好的Prompt就够了,有些需要RAG,有些需要Fine-tuning,有些需要搭一个完整的Agent系统。
不存在一个万能方案。但如果你理解了每一层在做什么,你至少能做出正确的判断。
这大概就是这个系列想传达的东西。
永远对世界保持好奇。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
延伸阅读
- MCP,给AI一个通用的万能接口:MCP(Model Context Protocol)是AI世界的USB-C,解决了模型和工具之间N×M碎片化问题。这篇文章从USB-C类比讲起,带你理解这个正在重塑AI生态的开放协议。
- Function Calling,让AI学会动手干活的技术:AI什么都知道却什么都做不了?Function Calling让大模型从只会说话变成能动手干活。这篇文章用大白话聊透这个让AI Agent成为可能的核心技术。
- Fine-tuning,让AI学会「成为某个人」的技术:微调到底是什么?跟RAG和prompt有什么区别?LoRA和QLoRA又是什么?这篇文章用大白话聊透Fine-tuning,从概念到成本到实际应用场景。
- Claude Tag 不是重点,重点是所有人都在赌 AI 该住在哪里:Anthropic 发布 Claude Tag,一个住在 Slack 里的 AI 同事。但这不是一个产品新闻,而是一场关于 AI 如何融入工作流的路线之争的最新表态。嵌入派 vs 独立入口派,各家选择的背后是完全不同的生存逻辑。
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。