
最近这段时间,我在自己的工作流里做了一件事,把用了大半年的MCP全部干掉了,换成了Skill。
不是因为MCP不好用。坦率的讲,MCP刚出来的时候我是真的兴奋,觉得这玩意就是AI Agent的USB接口,以后所有工具往上面一插就完事了。Anthropic、OpenAI、Mistral抢着宣布支持,GitHub、Slack、Google Drive都出了官方MCP server,那阵势,你不用MCP都觉得自己落伍了。
我当时还在朋友圈发过,说这东西是AI基础设施的TCP/IP时刻。
但用了半年之后,我发现一个事情。
我的token在燃烧。
不是那种细水长流的消耗,是肉眼可见的、哗哗往外流的那种。我开始纳闷,明明就查个GitHub issue,为什么每次都要吃掉那么多context?后来我仔细一算,才发现问题有多离谱。
GitHub官方MCP,光是启动时把工具定义塞进上下文,就要吃掉将近50,000个tokens。后来他们优化了一版,降到了23,000。Flask的作者Armin Ronacher分享过,他用的Sentry MCP也要占掉8,000多tokens。而同样的事情,你让agent直接跑一条gh issue list呢?上下文开销是零。因为LLM在训练的时候已经见过无数遍这些CLI命令了,它本来就知道怎么用。
23,000 tokens是什么概念?大概相当于一篇一万五千字的中文长文。你还没开始干活呢,光是「准备工具」这个动作就先占掉了这么大一块地方。如果你同时接了三四个MCP,context窗口可能还没开始正经工作就已经满了一小半。

你想想看,这就好比你本来会骑自行车,但有人非要给你装一个「骑车协议适配器」,每次骑之前先花五分钟读一遍说明书。你说有没有用?有。有没有必要?大部分时候真没有。
这就是我开始认真研究Skill的起点。
说到这个Skill到底是什么,其实概念简单到有点让人不敢相信。一个文件夹,里面放一个SKILL.md(本质就是一份Markdown文档),告诉AI遇到某类任务该怎么处理。可以选配一些脚本和资源文件。没有JSON schema,不需要架server,不需要处理什么transport协议。一个会写markdown的人就能做出一个有用的Skill。
我第一次看到这个设计的时候,反应是,就这?
然后我试了一下,反应变成了,卧槽,就这就够了???
Anthropic是2025年10月推出Skills的。到了年底,Simon Willison在年度回顾里直接说MCP可能只是「一年的风潮」。Armin Ronacher更彻底,直接宣布他把所有MCP都换成了skills,理由是skills更容易维护,而且LLM本来就善于用bash,加上指引就够了。
一个趋势越来越明显,真正在一线干活的人,在用脚投票。
回到token这块,我来拆解一下为什么Skill能省这么多。这个事情的底层逻辑其实不复杂,但很多人没想清楚。
MCP的问题出在它的「单次操作模式」。 每一次工具调用,中间结果都要返回给LLM。你调一次,结果塞进context。再调一次,结果又塞进context。工具一多、步骤一长,光是中间暂存数据就能把context塞爆。这不是某个MCP实现得不好的问题,这是协议层面的结构性问题。
打个比方。MCP就像你雇了一个跑腿,每次他去办一件事,都要跑回来跟你当面汇报一遍,你听完说「好,下一步去做这个」,他再跑出去。来回跑腿的过程本身就在消耗你的时间和注意力(也就是context)。而Skill更像是你给这个跑腿一份完整的行动指南,「去把这三件事办了,结果记在本子上,最后汇总给我就行」。中间那些来回跑的消耗直接省掉了。
我举一个更具体的例子。假设你要同时查询三个来源的React相关文档和issues。
用MCP的流程是这样的,启动时把三个MCP的tool schema全部传给LLM,消耗context。调用第一个MCP,结果返回给LLM,消耗context。调用第二个,结果又返回,又消耗。第三个,同理。最后LLM拿着这三坨数据整理出报告。每一步都在烧token,每一步中间结果都占着你的上下文窗口。五步操作,五次context膨胀。
Skill可以怎么做呢?启动时只传一个轻量目录,告诉agent有哪些skill可用,消耗极少。执行第一个skill,结果存到硬盘a.md,不占context。第二个,存到b.md。第三个,存到c.md。然后跑一个脚本从三份文件里抽取需要的内容,产出最终报告。视需要再把报告给LLM看,或者留在硬盘等LLM之后用Read tool读取。中间结果全程不需要经过LLM的上下文窗口。
关键差异就在这里,Skill把硬盘当缓存,中间结果不需要每次都返回给LLM。
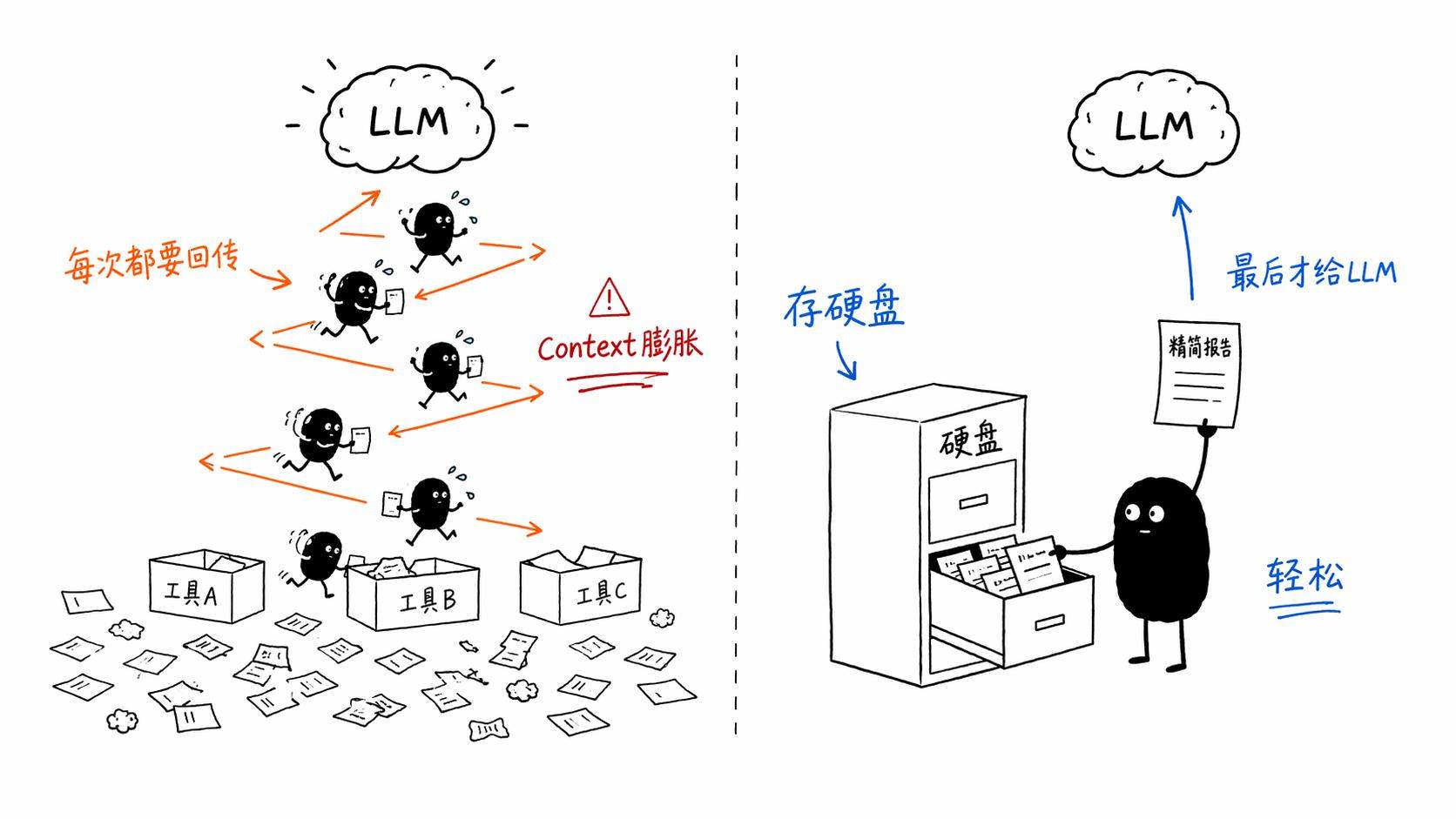
这个设计在coding agent上特别自然,因为Claude Code、Codex CLI这些工具本来就有shell和文件系统访问能力。硬盘对它们来说就是一个无限大的、零token成本的暂存区。而MCP因为协议设计的原因,不得不把所有中间数据都塞进LLM的context里过一遍。
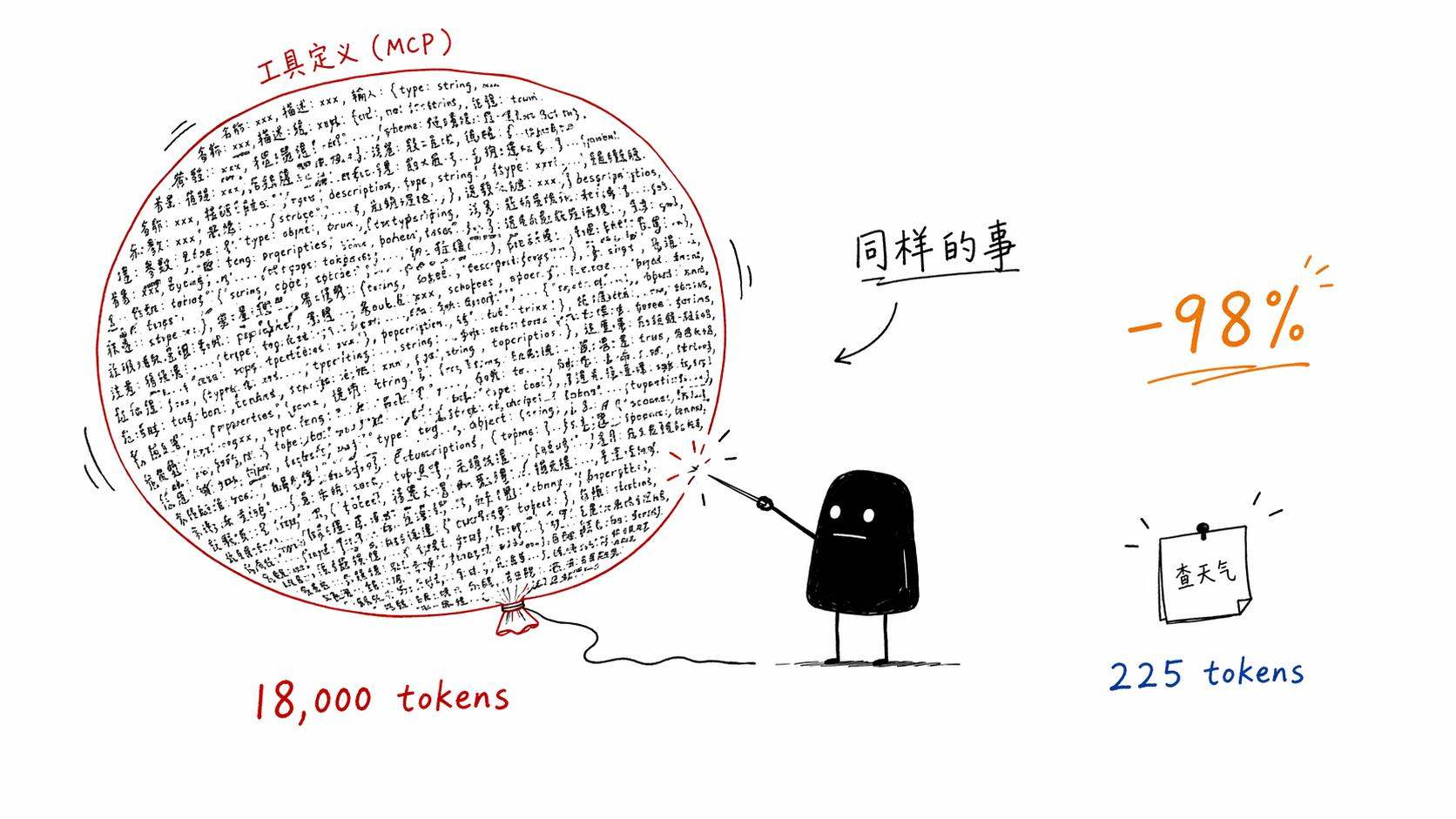
这个差异有多大?Mario Zechner做过一个很直观的对比。让agent控制浏览器,Playwright MCP需要18,000 tokens的工具定义,Chrome DevTools MCP也要13,700 tokens。他自己写了四个小Node.js脚本(启动、导航、执行、截图)加一份225 token的README,agent照样能完成任务。上下文消耗减少了98%。
98%。你敢信???
而且还没完。Skill被载入前,在上下文里只占几十个tokens的摘要描述。只有agent判断「这个任务需要用到这个skill」的时候,才会展开完整内容。这就是所谓的lazy loading。MCP呢?连接的时候就把所有工具定义一股脑塞进来了,不管你这次用不用得到,token先占着再说。
这种差距在你只接一两个工具的时候可能感觉不明显。但当你的agent需要十几个能力的时候,MCP的token开销是线性增长的,而Skill因为lazy loading的设计,只有实际触发的那几个会消耗context。差距会越拉越大。
而且Skill还有一个更骚的操作。因为LLM本来就会写代码,你可以让它根据需求当场生成一段脚本来组合多个skill。本来vibe coding就是大量依赖LLM写代码的能力嘛,为什么不发挥它的长处?相当于LLM从一个「工具调用者」变成了「工具制作者」,这个升维是质的变化。
想象一下,三个skill的查询结果分别存在硬盘上,LLM临时写一段代码把它们合并、去重、提取关键信息,最后产出一份精简的报告。整个过程中LLM的context里只需要放那段几十行的脚本代码和最终结果,而不是三份原始数据的全部内容。token消耗可能只有MCP方案的十分之一甚至更少。
说真的,我自己切换之后最直观的感受就是,同样的任务,以前经常跑到一半context就快满了需要开新对话,现在一口气能跑完整个流程还绑绑有余。体验上的差距是肉体可感的。
顺着上面的再聊聊,MCP还有一个让我越来越难忍的问题,就是维护成本。
MCP需要跑一个server process,不管是本地还是远程的。那结果就是你得维护它。API改版了要跟着改,依赖更新了要跟着更新,哪天server挂了你还得去排查。我之前用的一个MCP,就因为上游API改了个字段名,直接挂了两天我才发现。而一个SKILL.md呢?它就是一个文件。它不会crash,不会内存泄漏,不会因为某个依赖包升级了就罢工。几乎零维护。
Peter Steinberger说了一句话我觉得特别到位,「依我看,大多数MCP都只是行销部门用来打勾自豪的东西。几乎所有MCP其实都应该只是CLI。我自己就写过5个MCP,所以我这样说有根据。」
这话听着有点刺耳但我觉得他说的是事实。很多MCP的本质就是把一堆CLI命令用JSON schema描述一遍,然后让LLM通过工具调用的方式执行。和直接让agent跑shell命令相比,多了协议层的开销,却没带来对等的收益。你花了一堆精力去写工具定义、处理输入输出schema、维护server进程,最后实现的效果和一行gh pr list --state open一模一样。
Simon Willison说得更直接,「如果你的agent可以执行任意shell命令,它就能做任何可以通过在终端输入命令完成的事。」
这句话从根本上动摇了大多数MCP的存在理由。
还有一个点我觉得很多人忽视了。同一份SKILL.md在Claude Code、Codex CLI、Gemini CLI都能用。不像MCP经常要针对不同client做适配,skill天然是跨平台的。因为它就是markdown加脚本,不依赖任何特定的协议实现。Skills现在也已经走向开放标准了,官网agentskills.io提供完整规格书,OpenAI Codex也宣布支持,不再只是Claude的专属机制。
当然了,我不是说MCP完全没用。我自己也还保留了两三个MCP在用。我始终觉得评价技术不能非黑即白,那样太幼稚了。
有几个场景MCP确实有它的价值。第一个是需要OAuth认证的外部系统,agent要代你完成认证流程并安全保管token,MCP client目前有完整的解法。这是Skill目前确实还没完全覆盖的场景,不过Anthropic的工程师表示正在积极解决。第二个是需要维持有状态session的场景,比如交互式调试。Armin Ronacher做的pexpect-mcp就是拿来跟LLDB做互动式除错的,需要维持session状态,CLI确实不太好处理。第三个是快速演进的领域,如果你的SDK版本天天在变,MCP接的是文档系统,文档一更新agent拿到的context就自动是最新的,不用你手动去改skill里的示例代码。
LlamaIndex团队就分享过他们的实战经验,在开发LlamaAgents Builder时同时试了MCP和Skill两种方案,最终选了MCP,关键原因就是他们的SDK更新太频繁了。这个场景下MCP的「single source of truth」优势是Skill很难比的。
另外Skill也有一个理论上的弱点,就是非确定性执行。MCP是确定性的函数调用,输入固定输出固定,agent只需要决定「调哪个工具」。Skill依赖LLM解读自然语言指令,有两层风险,误解指令加上选错方案。同一份skill可能产生不同的执行路径。不过我自己的实际体验是,现在的LLM已经足够聪明了,只要skill写得清楚,误解的概率其实很低。
但这种场景占多大比例?我自己的感受是,日常工作中大概80%以上的任务,Skill加上CLI就完全够用了。剩下那20%才需要动用MCP。
而且这两者不是零和的。 已经有人做了mcporter这个工具,可以直接把现有MCP转成Skill使用。现有的MCP可以被包进Skill来执行,等于Skill继承了MCP的所有功能,同时享受Skill自己的优势。从这个角度看,Skill更像是MCP的超集。或者说,MCP 2.0。
我有时候觉得,AI工程这个领域特别容易犯一个错误,就是把事情搞复杂。一个新协议出来,大家一窝蜂往上冲,各种wrapper、middleware、gateway层层叠加,到最后需要一个MCP gateway来管理你的MCP,需要一个discovery middleware来帮agent找到正确的MCP。你在协议上面又叠了两层协议。。。回头一看,原来最简单的方案一直就在那里。
LLM本来就会用命令行。它训练的时候看过海量的代码和文档。你只需要用人话告诉它「遇到这类问题,按这个思路处理」,它就知道该怎么做了。这不就是Skill在做的事情吗?一份markdown,几个脚本,搞定。

与其问「要不要用MCP」,更好的问题可能是,这件事agent直接跑CLI或者写个脚本就能做到吗? 如果可以,先从那里开始。
简单的方案往往就是最好的方案。这句话在AI时代反而比以前更加成立了。因为LLM本身已经足够聪明了,很多时候你需要做的不是给它更多工具,而是给它更少的束缚,让它用自己已经知道的方式去解决问题。
这让我想起软件工程里一个老生常谈的道理,最好的代码是你不需要写的代码。放到AI agent这个语境里就变成了,最好的工具协议是你不需要的那个协议。
反正我是回不去了。
延伸阅读
- MCP,给AI一个通用的万能接口:MCP(Model Context Protocol)是AI世界的USB-C,解决了模型和工具之间N×M碎片化问题。这篇文章从USB-C类比讲起,带你理解这个正在重塑AI生态的开放协议。
- Hermes Skill 太多记不住?我做了一个活跃度统计插件:当 Hermes Skill 堆到几十个,真正的问题不是继续装,而是看清谁高频、谁吃灰、谁值得维护。我给 Hermes Web 补了一块活跃度统计面板,专门解决这个可见性问题。
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。