故事是这样的。
上一篇我聊RAG的时候,反复提到一个词,embedding。当时我说「用embedding model把文字转成向量」,然后就没展开了。评论区和私信里好几个朋友问我,这个embedding到底是个什么东西?向量又是啥?为什么文字能变成数字?
坦率的讲,这个问题我自己之前也只是「知道有这么个东西」的状态。知道它很重要,知道它是RAG、语义搜索、推荐系统这些东西的底层基建,但要我认真解释清楚它到底在干嘛,我还真说不太上来。
所以这两天我就专门花时间研究了一下。今天这篇,就是把我理解到的东西用大白话讲出来。
如果你跟我一样,之前对embedding的认知停留在「好像是把文字变成数字」这个程度,那这篇应该能帮你把整个画面串起来。
先从一个最朴素的问题开始。
计算机只认识数字。0和1,整数,浮点数,它只跟数字打交道。但我们人类的信息载体是文字、图片、声音、视频这些东西。那问题来了,你想让计算机「理解」一句话的意思,你得先把这句话翻译成计算机能处理的格式。
最简单的翻译方式是什么?给每个词编个号。
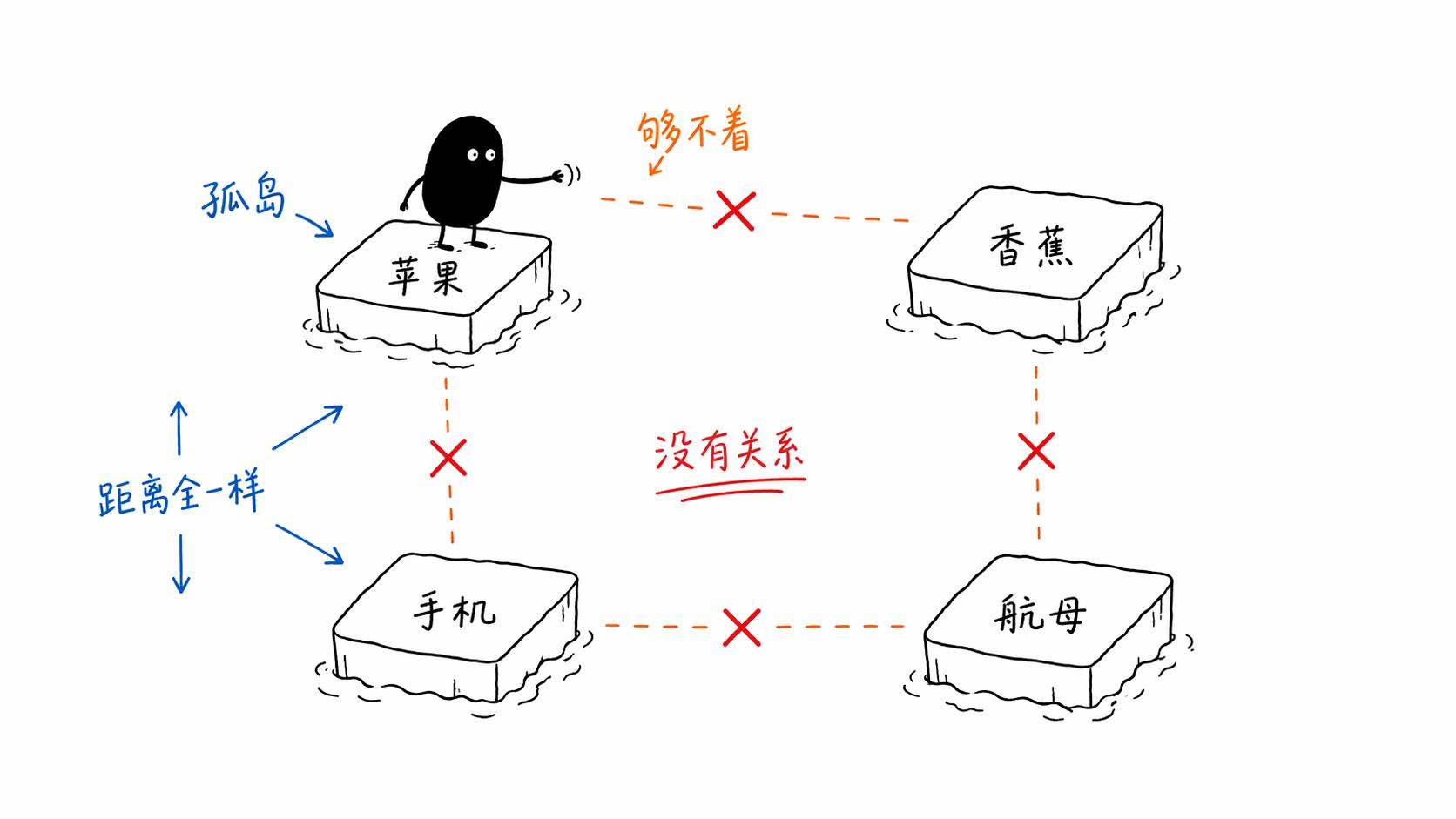
比如你有一个字典,里面有10000个词。「苹果」是第3721号,「香蕉」是第892号,「手机」是第5533号。这种方式叫one-hot编码,每个词用一个超长的向量表示,向量的长度等于字典大小,只有对应位置是1,其余全是0。
这种方法能用,但有一个致命的问题。
它完全不包含任何语义信息。
在one-hot的世界里,「苹果」和「香蕉」的距离,跟「苹果」和「航母」的距离是一样的。计算机看不出来苹果和香蕉都是水果、它们之间应该更「近」。每个词都是一座孤岛,词和词之间没有任何关系。
你想想看,如果你是一个搜索引擎,用户搜「如何种植苹果」,你只能精确匹配包含「苹果」这个词的文档。那些写了「果树栽培技术」的文档,虽然讲的是同一件事,但因为没出现「苹果」这个词,你就搜不到。
这就是embedding要解决的问题。
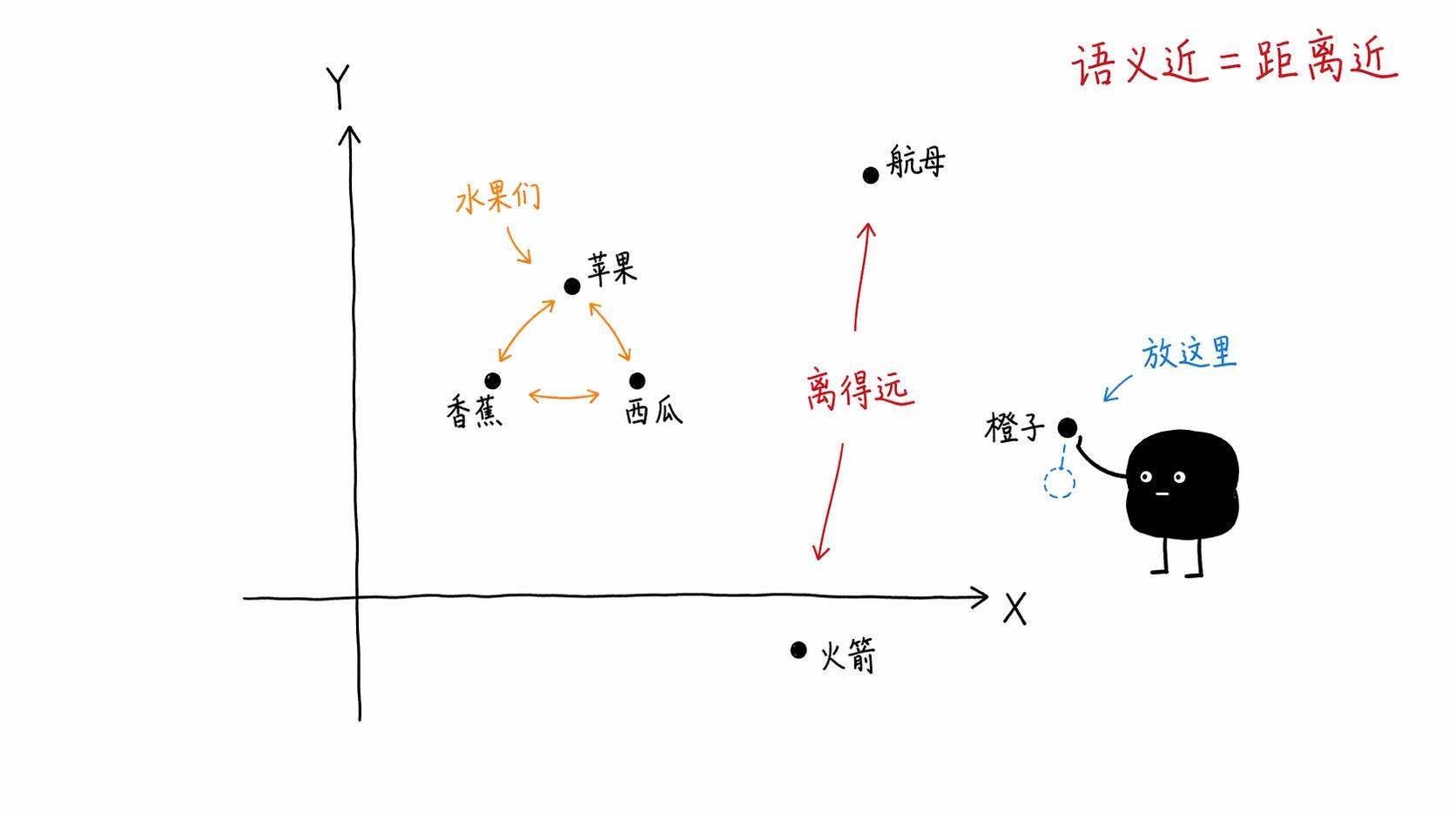
Embedding的核心想法是,把词(或者句子、段落、图片、任何东西)映射到一个连续的数学空间里,让语义相近的东西在这个空间里也互相靠近。
怎么理解这个「数学空间」呢?我觉得Google之前有一个例子讲得特别好。
想象你要给各种食物建一个embedding。你可以用两个维度来描述食物,一个维度是「三明治程度」(从纯汤/饮料到硬核三明治),另一个维度是「甜点程度」(从咸食到甜食)。这样每种食物就可以在一个二维平面上找到自己的位置。
汉堡在「三明治程度高 + 甜点程度低」的位置。冰淇淋在「三明治程度低 + 甜点程度高」的位置。奥利奥三明治冰淇淋可能在两个维度都偏高的位置。
这就是embedding在做的事情。只不过真实的embedding不是2个维度,而是几百甚至几千个维度。每一个维度都捕捉了某种语义特征,有的维度可能代表「正式程度」,有的代表「情感色彩」,有的代表「话题领域」。具体每个维度代表什么,模型自己学出来的,我们人类不一定能准确说出每个维度的含义。
但重要的是结果。训练好之后,语义相近的东西,在这个高维空间里的坐标就是接近的。
「今天天气真好」和「今天阳光明媚」的向量之间的距离,会远小于「今天天气真好」和「量子力学的基本原理」之间的距离。
这一下子就让计算机具备了一种粗糙但有效的「理解语义」的能力。
我觉得这件事最精妙的地方在于,它把一个本来很模糊的概念(两句话像不像)变成了一个可以精确计算的数学问题(两个向量的距离是多少)。
说到距离,顺便提一下。衡量两个向量之间相似度最常用的方法叫余弦相似度(cosine similarity)。不用理解数学细节,你只需要知道,两个向量方向越一致,余弦相似度越接近1,代表语义越相似。方向完全相反就是-1,毫无关系大概在0附近。
好,理解了embedding是什么之后,聊聊它是怎么来的。
这个领域的发展史其实挺有意思的,我简单捋一下。
2013年,Google的Tomas Mikolov团队发了一篇论文,提出了Word2Vec。这基本上是让embedding这个概念真正火起来的里程碑式工作。Word2Vec的思路很朴素,一个词的含义由它周围的词决定。你经常看到「巴黎」和「法国」出现在一起,「东京」和「日本」出现在一起,那模型就会学到这几个词之间有某种关系。
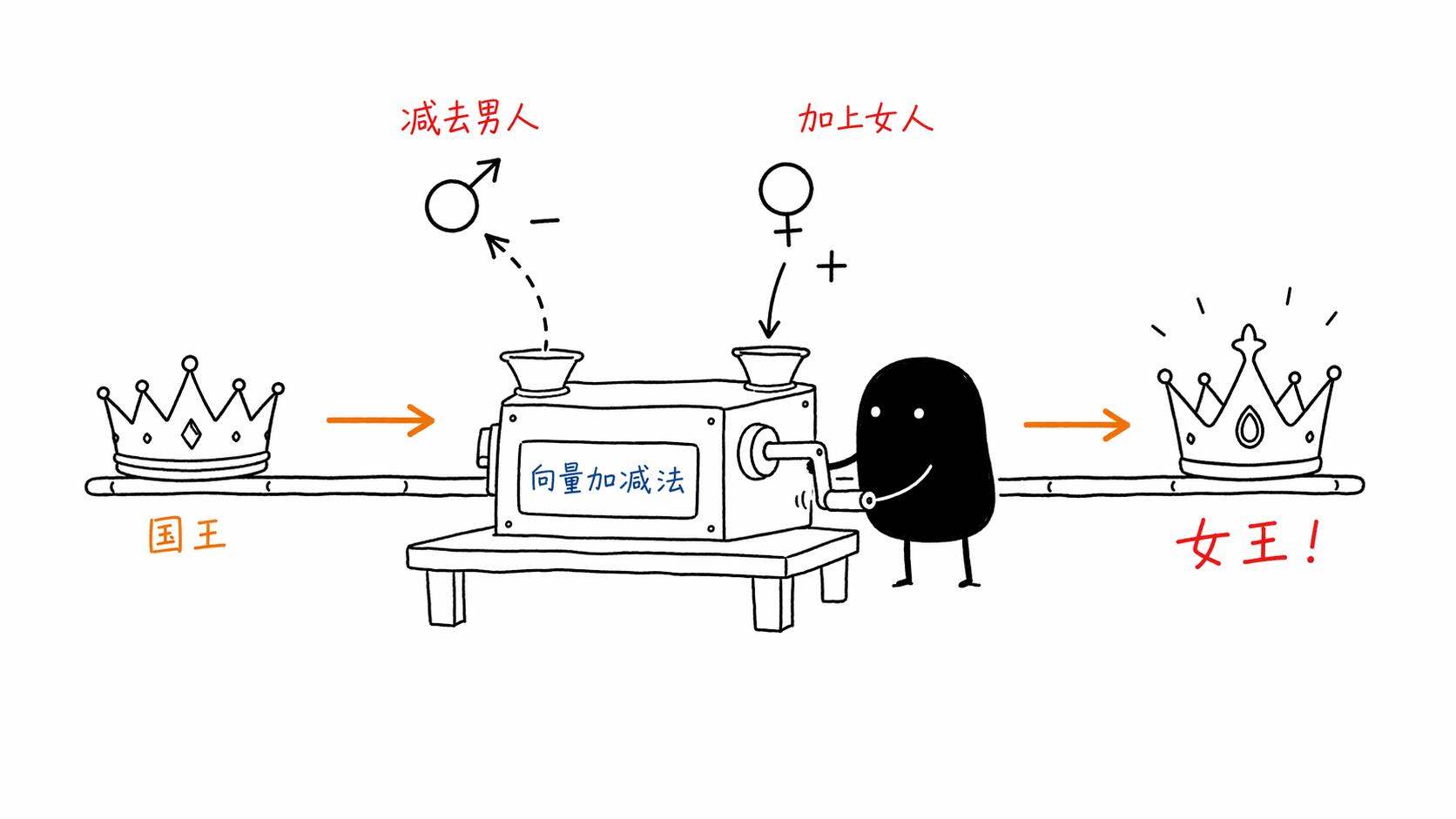
Word2Vec训练出来的向量有一些很神奇的性质。最经典的那个例子,「国王」的向量减去「男人」的向量加上「女人」的向量,结果最接近「女王」的向量。向量空间里居然能做语义级别的加减法,当年这个结果出来的时候整个NLP圈子都震了。
但Word2Vec有一个很大的局限,它给每个词只分配一个固定的向量。「苹果」在「我吃了一个苹果」和「苹果发布了新iPhone」里是完全相同的向量。显然这不对,同一个词在不同语境下意思可能完全不同。
2018年,BERT来了。Google的另一篇重磅论文。BERT的核心进步是,它给出的embedding是上下文相关的。同一个词在不同句子里会得到不同的向量。这就把一词多义的问题解决了。
再后来就是这两年的事了。专门为embedding任务训练的模型越来越多,越来越强。不再是把通用语言模型的中间层拿来凑合用,而是专门针对「判断两段文本是否相似」这个任务去训练。
2024到2025这两年,embedding模型已经变成了一个卷得飞起的赛道。
让我说几个现在主流的选手。
OpenAI的text-embedding-3系列。分small和large两个规格,small是1536维,large是3072维。价格很便宜,small版本100万token才2分钱(美元),是目前用得最多的商用embedding模型之一。它还支持一个很骚的特性叫维度缩减,你可以指定只要前256维或者前512维,精度会损失一点但存储和计算成本大幅降低。
Cohere的embed-v4。1024维,支持100多种语言,而且同时支持文本和图片的embedding,是目前为数不多的多模态embedding模型之一。
阿里的通义embedding系列。最新的是基于Qwen3架构的text-embedding-v4,维度可以灵活配置到2048。国内场景用得很多,中文效果尤其好。还有一个开源的叫BGE-M3,支持100多种语言,可以自己部署,不用给任何人交API费用。
Voyage AI的voyage-3-large。2048维,在代码和技术文档的embedding上效果特别好,很多做代码搜索的团队在用。
你可能注意到我一直在提「维度」这个数字。1536维、3072维、2048维。这个数字代表什么?
维度就是这个向量有多长。1536维的意思是,每一段文本被转成了一个由1536个数字组成的数组。
维度越高,理论上能捕捉的语义信息越丰富,区分度也越高。但代价是存储空间更大、计算距离时更慢。这就是一个精度和成本之间的trade-off。实际选型的时候,1024到1536维对大多数场景已经够用了,除非你的数据量特别大或者对精度有极端要求,否则没必要上3072维。
说完模型,聊聊embedding到底能干什么。
第一个,也是最直接的应用,就是语义搜索。
传统的搜索引擎说到底就是在做关键词匹配。你搜「头疼怎么办」,它去找包含「头疼」这个词的页面。但如果一篇文章写的是「偏头痛的自我缓解方法」,没有出现「头疼」两个字,传统搜索就找不到。
有了embedding之后,你可以把所有文档都转成向量存起来,用户搜索的时候把搜索词也转成向量,然后找距离最近的那些文档。因为「头疼」和「偏头痛」在向量空间里本来就很近,所以即使用词不同也能找到。
这就是为什么现在很多搜索产品变得越来越「聪明」了。你搜的词和文档里的词不一样,但它依然能找到相关结果。背后大概率就是在用embedding做语义匹配。
第二个,RAG。
这个我上一篇已经聊过了。RAG的核心流程里,「检索」那一步就是靠embedding实现的。把知识库的文档切块后全部转成向量,用户提问也转成向量,然后找最近的几个块。embedding的质量直接决定了RAG系统检索的准确度。
很多人做RAG做不好,不是模型不行,不是prompt不行,是embedding选的不对或者分块策略有问题,导致检索出来的内容压根就不是用户想问的。
第三个,推荐系统。
Airbnb在2018年发了一篇很经典的论文,讲他们怎么用embedding做房源推荐。他们把每个房源、每个用户的浏览行为都转成向量,然后在向量空间里做匹配。用户看过的房源聚集在空间里的某个区域,系统就从那个区域附近推荐新的房源。
Spotify用类似的方法做音乐推荐,把歌曲和用户偏好都映射到同一个向量空间。淘宝、抖音、YouTube的推荐系统里,embedding也是核心组件之一。
第四个,聚类和分类。
你有一堆客服工单,想自动归类。之前可能得靠人工打标签或者写一堆规则。现在把所有工单都转成向量,然后跑一个聚类算法,语义相近的工单会自然地聚到一起。投诉类的聚一堆,咨询类的聚一堆,bug反馈类的聚一堆。不需要提前定义类别,模型自己就能发现数据里的结构。
第五个,跨模态搜索。
这个是最近一两年特别火的方向。以前文本有文本的embedding,图片有图片的embedding,两个不在同一个空间里,没法直接比较。现在有一类模型(比如CLIP、以及阿里最新的通义多模态embedding)可以把文本和图片映射到同一个向量空间里。
这带来的变化是什么?你可以用一句话去搜图片。搜「一只橘猫趴在键盘上睡觉」,系统把这句话转成向量,然后去图片向量库里找最近的,返回的就是符合描述的图片。反过来也行,给一张图片,找语义最相关的文字描述。
Google Photos的「用自然语言搜照片」功能,底层就是这个原理。
聊到这里我想说一个自己的感受。
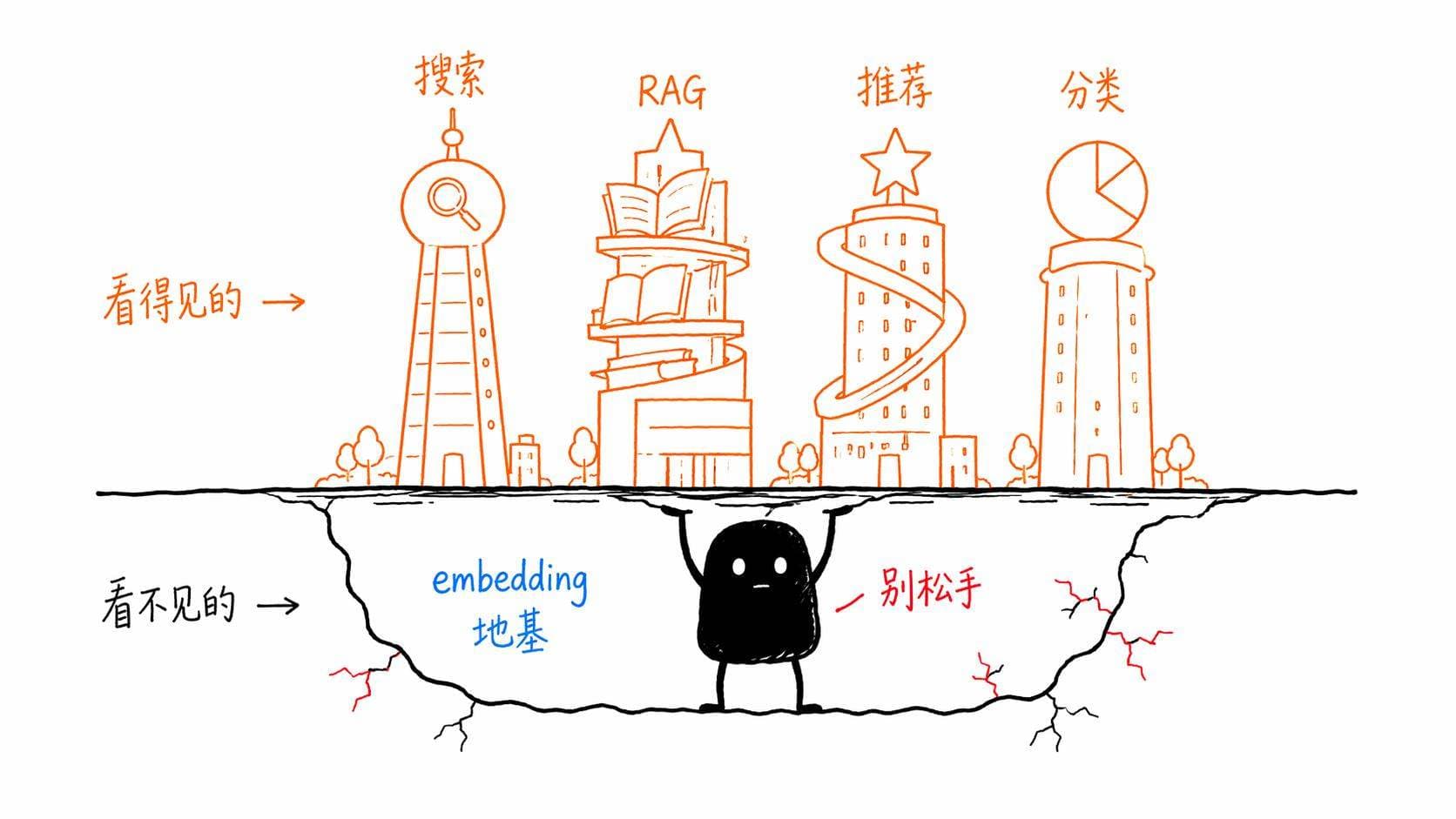
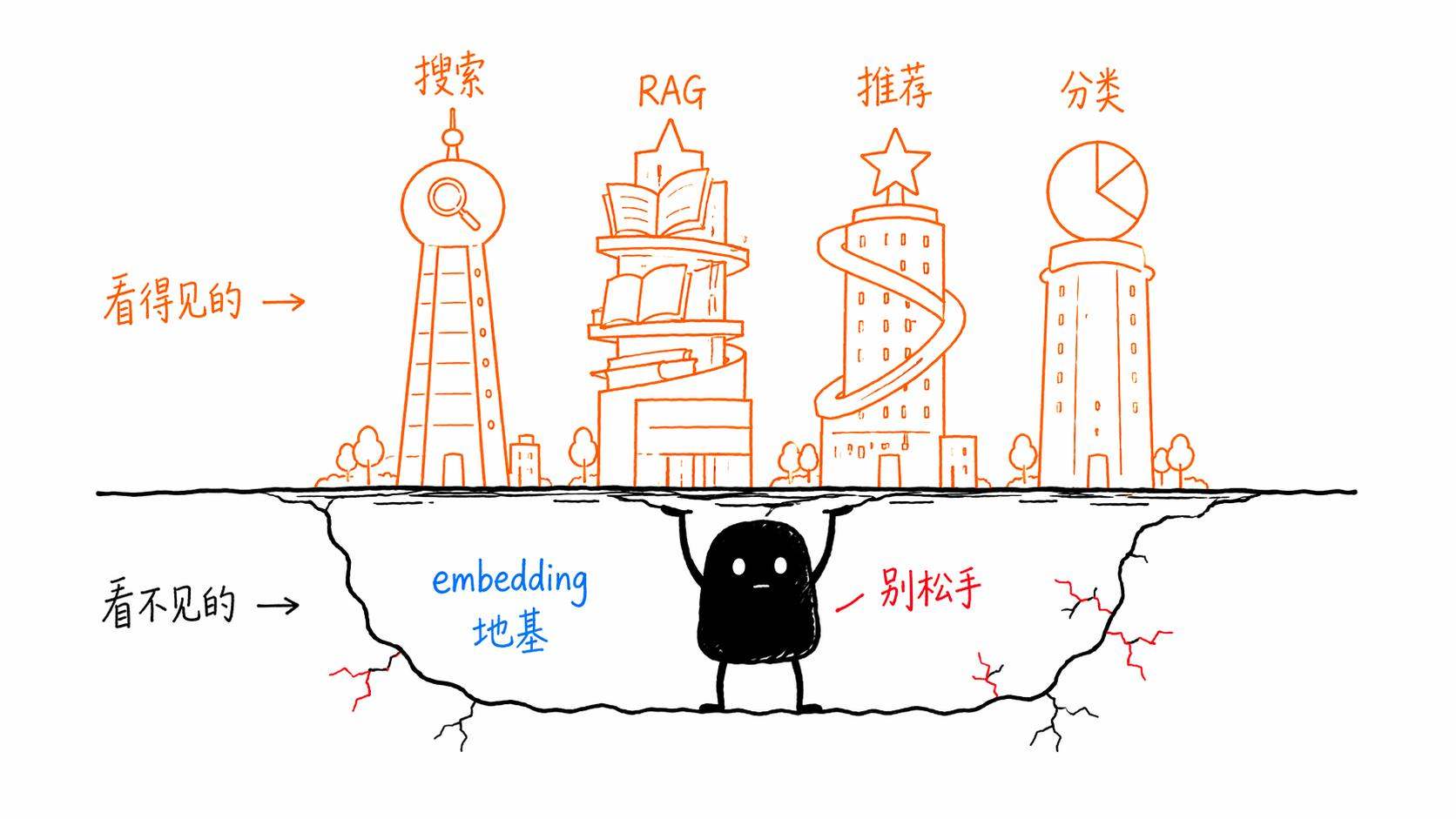
我在研究这些东西的过程中,越来越觉得embedding这个技术被严重低估了。大家一提AI就是ChatGPT、就是生成式AI,但其实embedding才是很多AI应用真正的「地基」。没有好的embedding,RAG做不好,搜索做不好,推荐做不好,分类做不好。
它就像水电煤一样,你平时看不到它,但离开它什么都转不了。
反正我现在的理解是,如果说大语言模型是AI的大脑,那embedding就是AI的感知系统。大脑再聪明,如果看不见听不到、感知不到外部信息的含义,也是白搭。embedding让AI能够「感知」到语言和信息的含义,然后大脑才有东西可以处理。
再展开讲一个我觉得挺反直觉的事情。
很多人可能会以为,embedding模型一定是越大越好、维度越高越好。但实际上不是这样。
我看到一个很有意思的benchmark结果。在MTEB(Massive Text Embedding Benchmark,目前最权威的embedding评测榜单)上,有些参数量只有几百M的小模型,在特定任务上的表现居然能超过好几个B的大模型。
原因是embedding这个任务跟生成任务不一样。生成需要「创造」新的内容,对模型容量要求高。而embedding更多是「理解」和「压缩」,一个精心训练的小模型在理解语义方面可能已经非常够用了,大模型多出来的那些参数对embedding任务的边际收益很小。
这对实际应用来说是个好消息。你不需要花大价钱跑一个超大模型来做embedding,用一个合适规模的模型就能达到很好的效果。成本可控,延迟也低。
最后聊一个我觉得代表未来方向的东西。
前面说的大部分都是文本embedding。但现在整个行业都在往多模态的方向走。文本、图片、音频、视频,所有模态的信息都可以映射到同一个向量空间里。
你想想这件事有多大。
一个用户在电商平台上,拍了一张照片说「我想找类似风格的衣服」。系统把这张照片转成向量,去商品库里找向量距离最近的商品。不需要用户描述颜色、款式、材质,一张图就够了。
或者一个视频平台,用户说「找一个这样的BGM」然后哼了一段旋律。系统把这段旋律转成向量,去音乐库里搜索语义最近的完整歌曲。
这些以前听起来像科幻的场景,现在技术上已经完全可行了。只是工程落地还需要时间。
多模态embedding最核心的突破在于,它打通了不同形式信息之间的隔阂。 以前文字是文字、图片是图片、声音是声音,它们活在不同的数据世界里。现在它们都变成了同一个空间里的坐标点,可以直接比较、直接关联。
我觉得这个事情的意义可能比大多数人想象的要大得多。它不只是让搜索变好了,它改变了计算机「理解」信息的基本范式。
怎么说呢,写到这里我自己的感受是,embedding这个技术确实没有ChatGPT那种「让所有人眼前一亮」的戏剧性。它不会生成让你惊叹的文章,不会画出让你震惊的图片。但它是让所有这些花哨应用真正能work的底层能力。
就像你不会因为一座大楼的地基打得好而赞叹,你赞叹的是地上那些漂亮的楼层。但没有那个地基,什么都立不住。
embedding就是AI世界的地基。沉默、不起眼,但不可或缺。
如果你正在做任何跟AI搜索、知识库、推荐相关的事情,花点时间搞明白embedding是绝对值得的投资。它不像大模型选型那样需要反复纠结,一旦选对了embedding方案,很多下游任务的效果都会跟着提升。
我自己在做RAG系统的时候,最大的一个教训就是,一开始我把所有精力都花在了prompt engineering和模型选型上,后来才意识到,检索准确率低的根源是embedding没选好。换了一个更适合中文的embedding模型之后,效果直接上了一个台阶。
坦率的讲,这个领域每隔几个月就会有新的模型出来,新的benchmark刷新记录。但底层的原理不会变,把信息映射到连续空间、用距离衡量相似度,这个范式在可预见的未来都会是主流。
永远对世界保持好奇。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
延伸阅读
- RAG,一个让AI学会翻书的技术:之前一直听说过RAG但没有深入了解过,今天花了一整天时间研究,用大白话聊透它的概念、原理、使用场景和最新进展。如果你跟我一样对RAG只停留在听说过的阶段,这篇应该能帮到你。
- 如何判断一个AI产品是不是在忽悠你:AI行业色素水浓度有点高。四层鉴伪框架教你识别:看技术在哪里、看有没有护城河、看它怎么说话、看它敢不敢让你试。知识不是用来炫耀的,是用来防身的。
- Prompt Engineering,用自然语言给AI编程的技术:Prompt Engineering不是那些满天飞的万能模板,而是一种用自然语言给AI编程的能力。五个核心原则、Context Engineering的进化、以及为什么你说话的方式决定了AI能帮你到什么程度。
- AI Agent,当AI学会自己搞定一整件事:AI Agent是Fine-tuning、Function Calling、MCP三大技术的集大成者。这篇文章从聊天机器人和Agent的本质区别讲起,拆解Agentic Loop的工作机制,坦诚讨论复合错误率的现实挑战,最终回答一个问题:当AI学会独立完成任务,什么能力变得更重要了?
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。