这两天看到一个特别有意思的事。
一个叫 Emil Kowalski 的设计工程师,把自己多年积累的 UI 动画原则,打包成了三个 Skill 文件,装到 Claude Code、Cursor、Codex 这些 AI 编码工具里面。
装完之后,这些工具写出来的前端代码,动画效果直接上了一个档次。
你可能会问,这有什么大不了的?
大不了的地方在于,他解决的不是「AI 能不能写动画代码」的问题。2026年了,哪个 AI 编码工具写不了动画?能写。都能写。
他解决的是「AI 写出来的动画为什么总感觉差点意思」的问题。
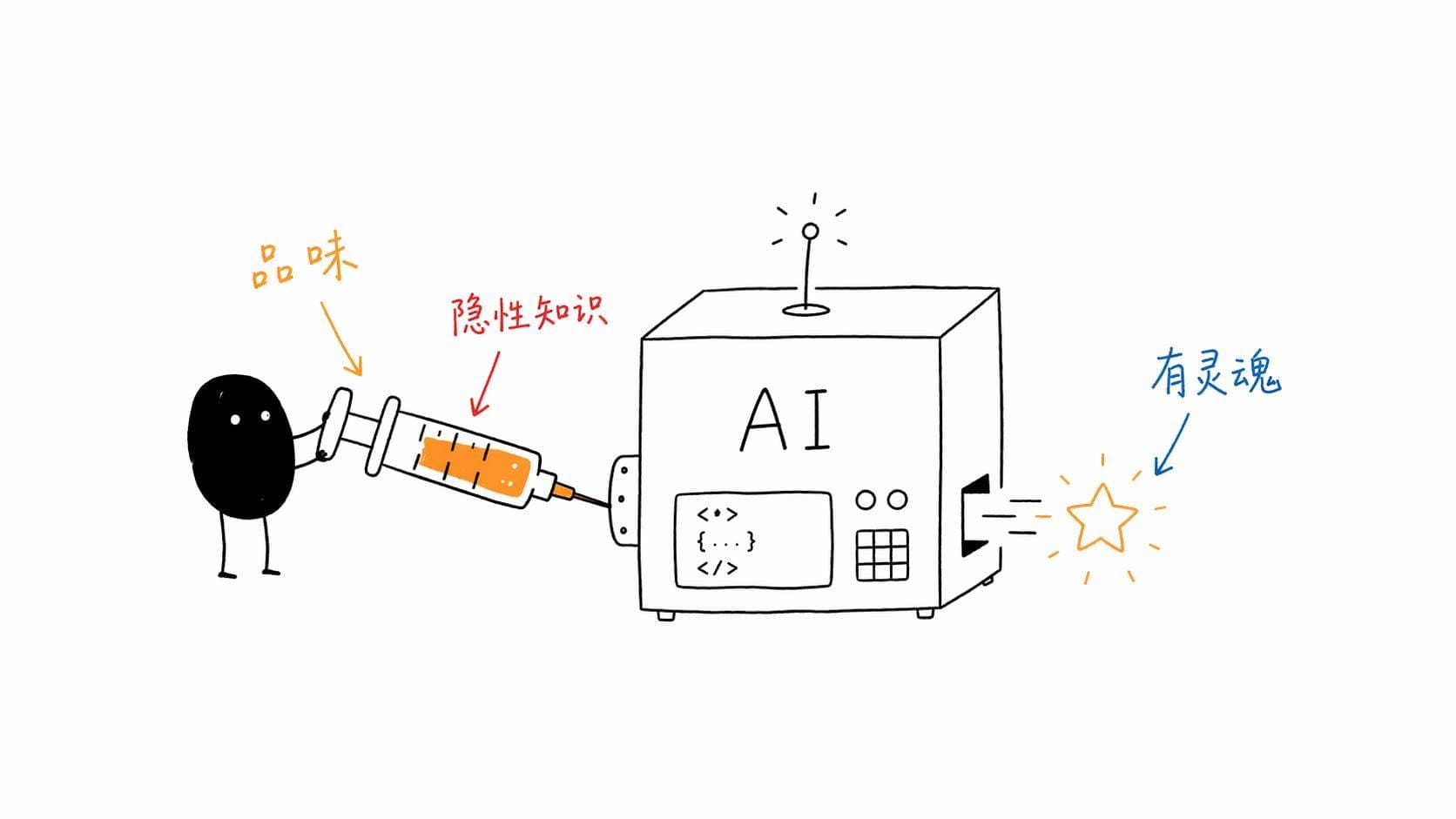
差的那个东西,叫品味。
Emil 在他的博客里写了一篇叫「Agents with Taste」的文章。里面有个观察我觉得特别精准,他说 AI 能写出正确的代码,但写不出「感觉对」的代码。
什么叫「感觉对」?
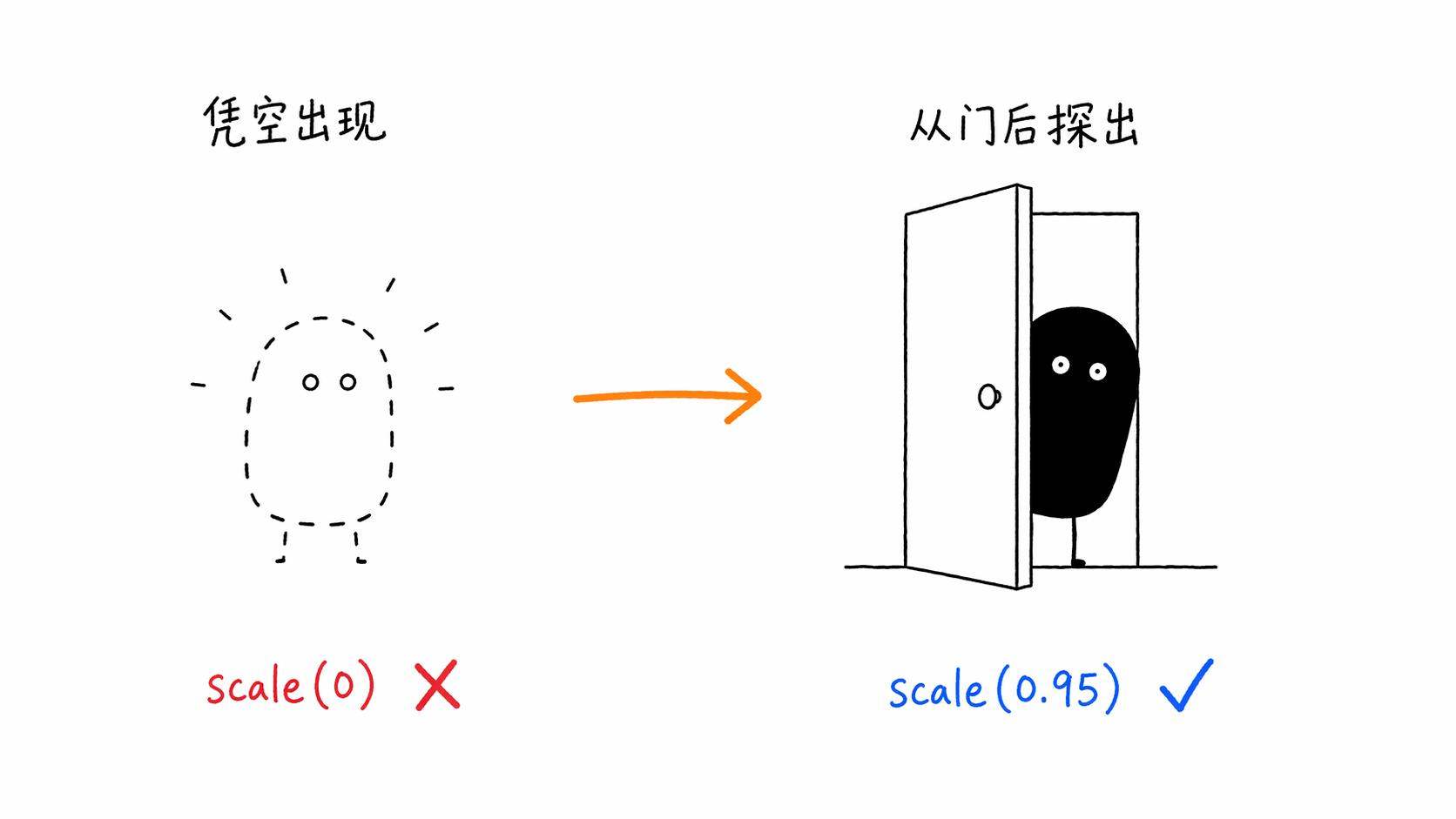
他举了个例子。一个弹窗出现的时候,AI 默认会写 scale(0) 到 scale(1) 的动画。从无到有,逻辑上完全正确。但视觉上就是怪。
为什么怪?因为现实世界里没有东西是从虚无中凭空出现的。一扇门是被推开的,一本书是被翻开的,一个物体是从某个地方移过来的。人的直觉会对「从零开始出现」感到不舒服,即使你说不出哪里不对。
Emil 的解法是,起始值改成 scale(0.95) 加 opacity: 0。元素不是从无到有,而是从「几乎就在那里」到「完全在那里」。差别非常微妙,就那么一点点,但感觉一下子就对了。
这种东西,看起来是个技术细节。但其实它背后的问题很大。
我先把时间线拉一下。
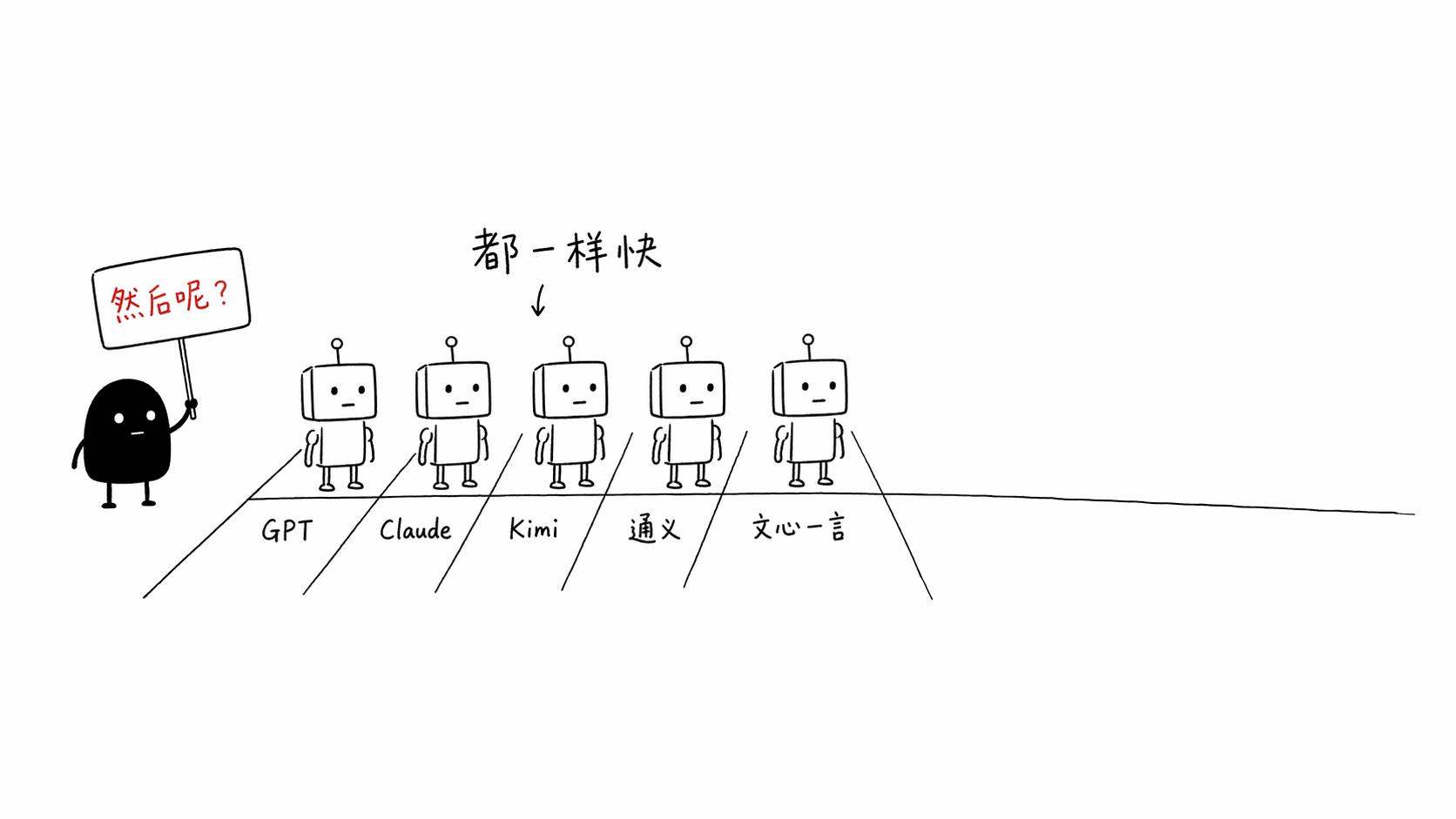
就在 Emil 发这些 Skill 的前一天,另一件事也发生了。GitHub 官方宣布 Kimi K2.7 Code 正式进入 Copilot 的模型选择器。这是 Copilot 里面第一个可选的开源权重模型。
也就是说,现在你在 VS Code 里面写代码,能选的 AI 模型至少有 GPT 系列、Claude 系列、Gemini,再加上 Kimi K2.7。性能呢?根据 Moonshot 公布的数据,K2.7 Code 在它自己的 benchmark 上比上一代提升了21.8%,已经能跟 GPT-5.5 和 Claude Opus 4.8 掰手腕了。
同一时间,一个叫 Senior SWE-Bench 的新 benchmark 也出来了。跟之前的 SWE-Bench 不同,这个专门评估 AI 做「高级软件工程师」级别任务的能力。不只是修 bug,还包括从自然语言需求出发实现完整功能。
你把这三件事放在一起看,会发现一个很有意思的画面。
模型越来越多。性能越来越趋同。Benchmark 越来越卷。
然后呢?
然后 Emil Kowalski 站出来说,你们这些 AI 编码工具,代码是写得越来越对了,但写出来的东西,就是不好看。
我觉得这是2026年 AI 编码领域最被低估的一个信号。
当性能不再是瓶颈的时候,品味就成了新的战场。
想想看,几年前大家选 AI 编码工具的逻辑是什么?谁能写出能跑的代码,选谁。后来是谁能写出 bug 少的代码,选谁。再后来是谁能理解复杂上下文、做多文件编辑,选谁。
这些能力现在基本都拉齐了。Kimi K2.7 能进 Copilot 就是最好的证据,开源模型都能跟闭源巨头打平手了。
Moonshot 公布的数据是,K2.7 Code 在 Kimi Code Bench v2 上比上一代提升了21.8%,token 消耗还降了30%。你去看 Hugging Face 上的模型卡片,它跟 GPT-5.5、Claude Opus 4.8 的得分已经在同一个量级了。这在两年前是不可想象的,那时候开源和闭源之间隔着一道天堑。
现在这道天堑填平了。大家站在同一条起跑线上。
那下一步比什么?
比谁写出来的东西,用起来更舒服,看起来更顺眼,感觉更「对」。
这个「对」是什么?就是品味。
我自己用 AI 写前端的时候感受特别深。让 Claude Code 帮我写一个按钮组件,功能完全没问题,点击、hover、disabled 状态都有。但动画就是差点意思。过渡太僵硬,时间曲线太线性,hover 的反馈没有重量感。
你说它错了吗?没有错。代码能跑,逻辑正确。
但如果一个真正懂设计的前端工程师来看,他会觉得这个按钮「没有灵魂」。
这种「有灵魂」和「没灵魂」的差距,普通用户说不清楚,但他们感觉得到。就像你用一个 App,说不上来哪里好,但就是觉得「舒服」。这个舒服背后,是几百个像 scale(0.97) 这样微小的决策累加出来的。
Emil 管这个叫「taste」,品味。他认为在 AI 时代,品味是那个让你跟其他人拉开差距的东西。因为 AI 帮每个人都跨过了「能做」的门槛,但「做得好」依然需要人的审美判断。
有意思的是,他选择的解法不是「教用户怎么审美」,而是「把审美直接注入 AI」。
他怎么做的呢?他写了几个 Skill 文件。
第一个叫 emil-design-eng。这个 Skill 把他对 UI 细节的所有偏执都编码成了规则。
按钮按下去的时候,要有 scale(0.97) 的反馈。为什么?因为现实世界里你按一个按钮,它会微微凹下去。没有这个反馈的按钮就是「死的」。
弹出层的出现,不能从 scale(0) 开始。要从 scale(0.95) 加 opacity: 0 开始。为什么?因为从虚无中出现违反物理直觉。
动画时长不要超过200ms。为什么?因为超过200ms 用户就会觉得界面「慢」,即使它实际上没有变慢。
transition 不要用 all。为什么?因为 all 是懒人写法,你根本不知道它在过渡什么,而且性能也不好。
每一条都很小。但叠加在一起,差距就出来了。
第二个 Skill 叫 review-animations。这个更狠,它让 AI 变成了一个动画审查员。你写完代码之后让它审一遍,它会用一个 Before/After 的表格告诉你哪些地方不对劲。
比如,
| Before | After | 理由 |
| transition: all 300ms | transition: transform 200ms ease-out | 不用 all,明确指定属性 |
| scale(0) | scale(0.95); opacity: 0 | 现实世界里没有东西从虚无中出现 |
| 按钮没有 :active 状态 | :active 时 scale(0.97) | 按钮必须对按压有物理反馈 |
你看,每一条修改都不大。但每一条背后都有一个「为什么这样感觉更对」的设计直觉在支撑。
他做的事,其实是把隐性知识显性化了。
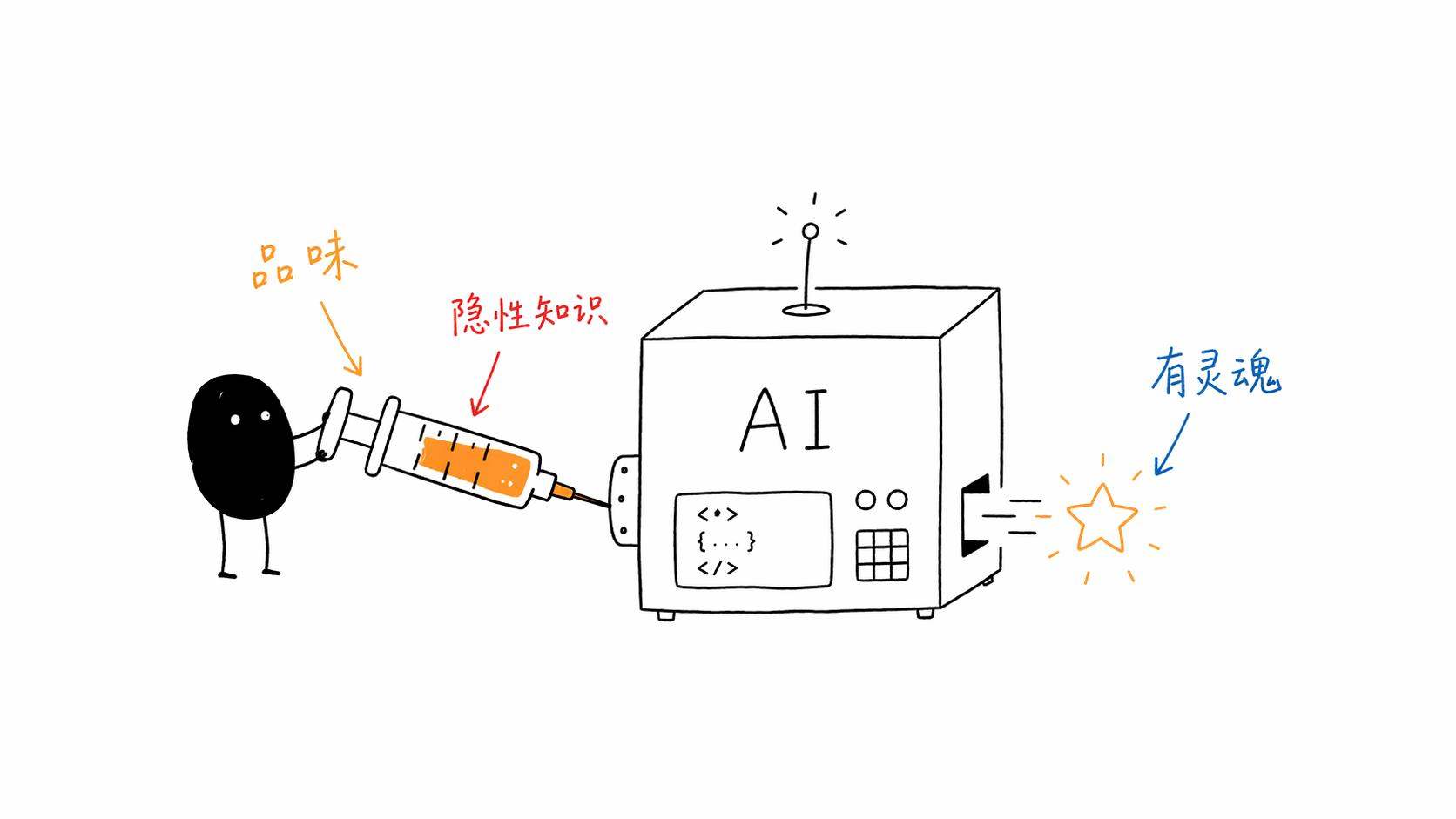
什么叫隐性知识?就是那些资深设计工程师「知道但说不清楚」的东西。为什么这个动画时长200ms 比300ms 好?为什么 ease-out 比 linear 舒服?为什么弹窗从 scale(0.95) 开始比从 scale(0) 开始更自然?
这些东西以前只存在于资深从业者的肌肉记忆里。你没个三五年经验,你不会「感觉」到这些区别。但现在 Emil 把这些肌肉记忆翻译成了 AI 能理解的规则,让 AI 也拥有了这种「感觉」。
我觉得这个思路对整个 AI 编码行业的影响会很大。
你想想,为什么 Senior SWE-Bench 要单独做一个「高级工程师」级别的 benchmark?因为初级任务已经被 AI 做烂了,大家分不出高下。那高级工程师跟初级工程师的区别到底是什么?
不只是能力更强。更重要的是判断力更好。
判断力是什么?就是面对多个都「能跑」的方案时,知道选哪个。这个选择的依据,很大程度上就是品味。
写一个排序函数,正确就行,品味的空间不大。但写一个前端界面、设计一个 API、架构一个系统的时候,「正确」的方案有一万种,「优雅」的方案可能只有那么几种。能在一万种正确方案里挑出最优雅的那个,这就是品味。
Senior SWE-Bench 的设计其实也暗含了这个认知。它的功能任务不是「写一个函数通过测试」,而是「根据一段自然语言描述实现一个完整功能」。这种任务里,AI 需要做大量的判断,怎么组织代码、怎么命名变量、怎么划分模块、哪些边界情况值得处理。这些判断的总和,就是品味的体现。
AI 正在从「会写代码」进化到「会写好代码」。而「好」的标准,不是机器定义的,是人注入的。
Emil 的 Skill 只是开始。
你想想看,如果这个模式跑通了,接下来会发生什么?
一个顶级后端架构师,可以把他对微服务拆分的直觉打包成 Skill。什么时候该拆、什么时候不该拆、拆到多细算过度设计,这些他脑子里的隐性规则,都可以让 AI 学会。
一个资深 iOS 开发者,可以把他对 SwiftUI 动画的偏好写成 Skill。什么场景用 spring、什么场景用 easeInOut、bounce 值多少看着最自然,这些经验可以直接赋能给 AI。
一个数据库专家,可以把他对 SQL 查询优化的审美打包成 Skill。这个 JOIN 写法性能没问题但不够优雅、那个索引策略能用但不是最佳实践,这些判断力可以被编码。
每个人都可以把自己最核心的「品味」,变成 AI 的一部分。
这就回到了一个更根本的问题。
AI 编码工具竞争的下一阶段是什么?
我觉得不再是模型性能之争了。Kimi K2.7 进 Copilot 说明一件事,性能这块大家已经够用了。Senior SWE-Bench 卷的那些高级任务,各家模型的差距也在快速缩小。
下一阶段的竞争,我觉得是生态竞争。具体来说,是「谁的平台上积累了更多高质量的 Skill」的竞争。
Cursor 有 Rules。Claude Code 有 CLAUDE.md 和 Skills。GitHub Copilot 有 Instructions。每家都在搞自己的「品味注入」机制。
模型是引擎,Skill 是灵魂。引擎可以趋同,灵魂不可以。
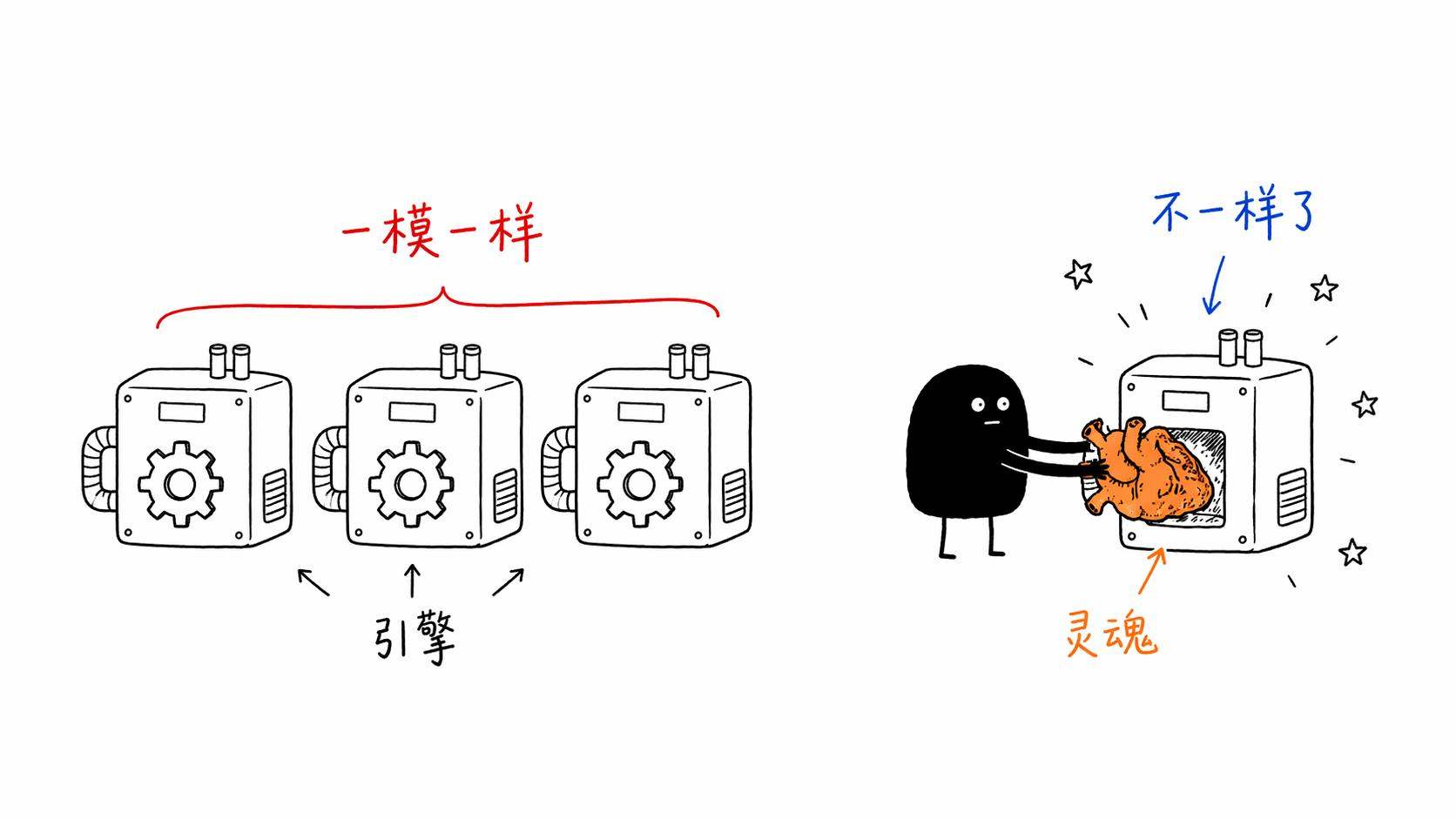
Emil 的 Skill 装在 Claude Code 上,它就有了设计工程师的审美。装在 Cursor 上,也一样。模型无所谓,重要的是那些规则。那些从人类经验中提炼出来的、关于「什么是好」的判断力。
我有时候觉得,这跟音乐行业的一个变迁很像。
2000年代,DAW(数字音频工作站)让每个人都能做音乐了。Logic、Ableton、FL Studio,门槛极低,人人都能拖拖拽拽做出一首歌。但结果是,大部分人做出来的东西都差不多。因为大家用的是同样的预设音色、同样的模板、同样的节奏模式。
真正让一首歌脱颖而出的,从来不是工具,而是制作人的耳朵。他知道 kick 的低频要切到多少赫兹、人声的齿音要用什么频率去压制、这首歌的空间感用什么混响参数最合适。这些东西,工具不会告诉你。
AI 编码现在也到了这个阶段。
工具已经足够强了。每个人都能用 AI 写出能跑的代码。但「能跑」跟「好用」之间的距离,就是品味的距离。
而品味这东西,不是一天能长出来的。它需要年复一年的训练、观察、积累。Emil 做了十年前端,才积累出那套「什么动画感觉对」的直觉。
但 Skill 机制的存在,让品味变得可以传递了。
你不需要自己花十年去积累,你可以站在别人十年经验的肩膀上。
我再多说一个 Emil 博客里让我印象很深的观点。
他说,训练品味的方法不是去「学习规则」,而是去「感受差异」。他在文章里做了个小游戏,给你看两个版本的动画,让你选哪个更好。选完之后你得写下来为什么选这个。
就这么一个动作,「把感觉翻译成语言」,他说这是 AI 时代最值钱的能力。
为什么?因为 AI 听得懂语言,听不懂感觉。你说「这个动画感觉怪怪的」,AI 没法帮你。但你说「这个弹窗的出现起始缩放值太小了,从虚无中出现不符合物理直觉,应该从0.95开始」,AI 就能精确执行了。
能把审美直觉翻译成精确语言的人,就是 AI 时代的品味架构师。
你看,这跟 Prompt Engineering 其实是同一件事。只是层次更高了。Prompt Engineering 是把「我想让 AI 做什么」翻译成精确语言。而品味注入是把「什么是好的」翻译成精确语言。前者是指令层的翻译,后者是审美层的翻译。
这话说回来,我自己最近也一直在想,能不能把我对内容创作的一些品味打包成类似的东西。什么样的标题有点击欲望、什么样的开头能留住读者、什么样的节奏让人读下去停不下来。这些东西我积累了几年,但一直是「脑子里知道」的状态。
如果有一天我能把这些写成一个 Skill,让 AI 也拥有我对内容的品味。。。想想还挺有意思的。
不过这个想法现在还只是个想法。我自己还没跑通。
回到 Emil 这件事上来。
我觉得他做的最有价值的事,不是那些具体的动画规则。而是他验证了一个路径,人的审美判断是可以被结构化、被编码、被注入到 AI 里面的。
而且他选择了一个极其聪明的落地方式。不是写一本设计指南让人去读,不是做一门课程让人去学(虽然他也有课程),而是直接打包成 Skill 文件,让 AI 自己去遵守。用户甚至不需要理解这些规则为什么好,只需要装上,AI 产出的代码自动就变好了。
这就像汽车的助力转向。你不需要理解液压原理,你只需要转方向盘,车自动帮你省力。
品味的民主化,可能就是这么发生的。不是每个人都去学十年设计,而是十年设计经验被压缩成一个文件,每个人都能用。
这条路一旦跑通,整个 AI 编码的竞争格局就会变。
不再是「谁的模型更聪明」。
而是「谁的 AI 更有品味」。
而品味的来源,是人。
说到底,AI 时代最值钱的东西,可能不是 AI 本身。而是那些能分辨「好」与「正确」的人。
因为「正确」这件事 AI 已经可以自己搞定了。但「好」这个标准,只有人能定义。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
延伸阅读
- 理解大模型:训练上下文 vs 推理上下文 vs 有效上下文这三个概念:模型标称支持100万上下文,不代表它用100万长度训练。实际上训练上下文、推理上下文、有效上下文是三个完全不同的概念。这篇文章从Llama 3、GPT-4、Gemini的真实技术细节出发,聊聊这三者的区别,以及为什么你的AI在长文档中间会开始胡编。
- 如何判断一个AI产品是不是在忽悠你:AI行业色素水浓度有点高。四层鉴伪框架教你识别:看技术在哪里、看有没有护城河、看它怎么说话、看它敢不敢让你试。知识不是用来炫耀的,是用来防身的。
- Prompt Engineering,用自然语言给AI编程的技术:Prompt Engineering不是那些满天飞的万能模板,而是一种用自然语言给AI编程的能力。五个核心原则、Context Engineering的进化、以及为什么你说话的方式决定了AI能帮你到什么程度。
- AI Agent,当AI学会自己搞定一整件事:AI Agent是Fine-tuning、Function Calling、MCP三大技术的集大成者。这篇文章从聊天机器人和Agent的本质区别讲起,拆解Agentic Loop的工作机制,坦诚讨论复合错误率的现实挑战,最终回答一个问题:当AI学会独立完成任务,什么能力变得更重要了?
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。