
最近在跟AI聊天的时候,我问了一个问题。
我说,你号称支持128K上下文,那你训练的时候,也是用128K长度的文本一路训过来的吗?
AI给了我一个很长的回答,里面有些对有些不对。但那一瞬间我意识到一件事——大部分人,包括几个月前的我自己,都默认了一个从来没验证过的假设。
就是,一个模型说自己支持100万token上下文,那它应该就是用100万token的超长文本训出来的吧?
不是的。
坦率的讲,这事儿比你想的要复杂得多,也有趣得多。
说真的,当我搞明白这里面的逻辑之后,我对整个AI行业的「参数营销」有了一种全新的理解。今天就来聊聊这个。
先说结论,你可以拿去直接刷新认知:一个模型宣称支持几百K甚至上百万的上下文窗口,不代表它从预训练第一天起就是用这么长的文本训出来的。 实际上,绝大多数模型的训练流程是先用短上下文学基础能力,后期再通过各种技巧把窗口「撑大」。
这就像一个人先花十年读短文章学会了语言和思考,然后再花几个月专门练习读完一整本500页的合同不漏细节。
顺序不能反。
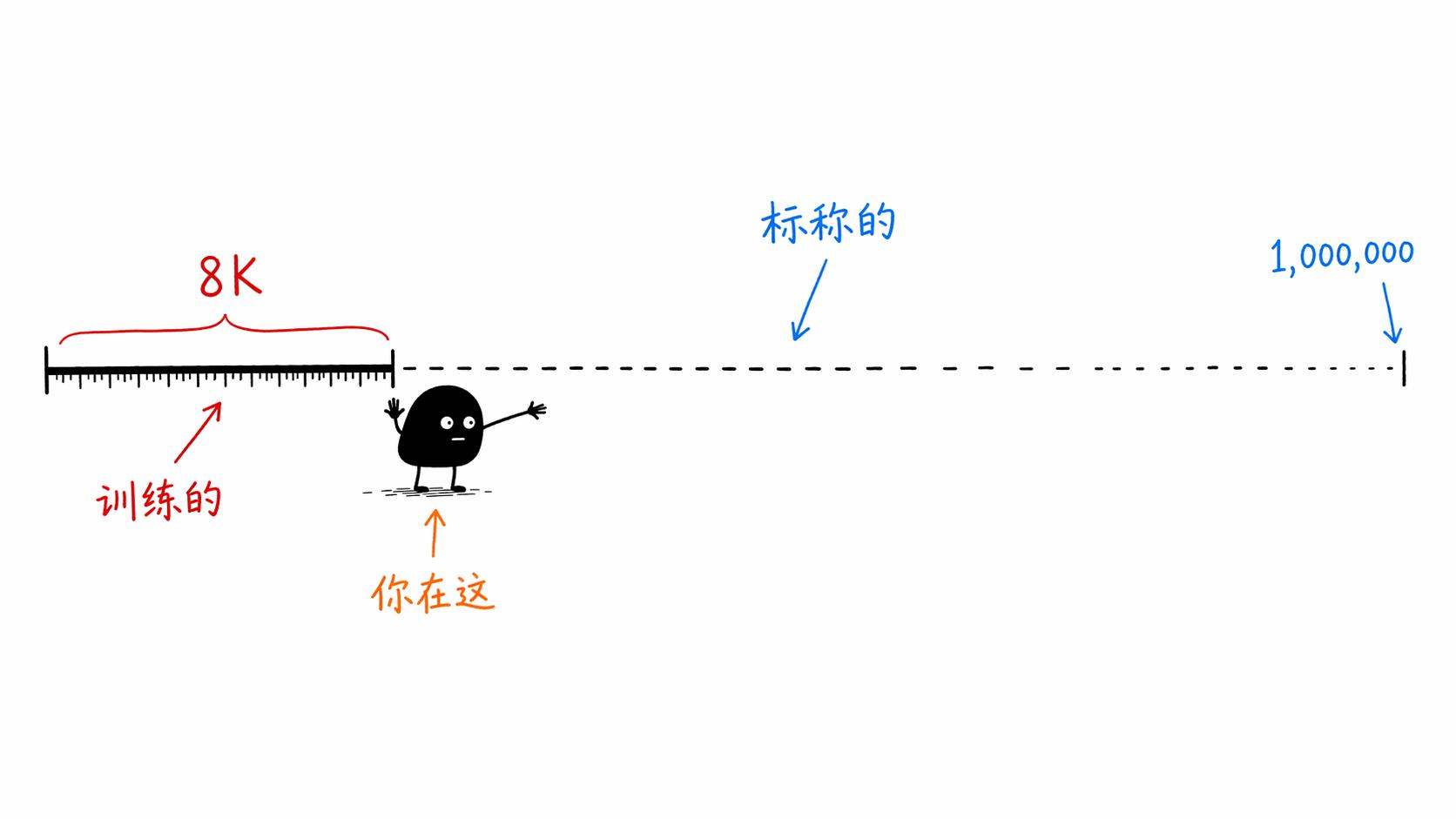
Meta在2024年发布Llama 3技术报告的时候,白纸黑字写了这件事。Llama 3的预训练主阶段,用的序列长度是8192个token。8K。就这么长。它是在15.6万亿个token的数据上,用8K的窗口一路训过来的。
然后呢?然后Meta说,我们把它扩展到了128K上下文。
你想想看,8K到128K,中间差了16倍。这不是简单的「训练的时候把文本切长一点」就能解决的事。Meta的技术报告提到,Llama 3的预训练分成三个主要阶段,短上下文预训练、长上下文文本预训练、以及多模态预训练。那个让你在产品页面上看到「支持128K」的能力,是在第二阶段专门补上去的。
而且补的过程也不是一步到位。根据公开信息,上下文长度是分六个阶段逐步扩展的,整个扩展过程消耗了大约8000亿个训练token。
这不是什么秘密。这是行业标准做法。
GPT-4最早发布的时候,上下文是8K。后来出了个32K版本,同样的模型权重,只是上下文窗口扩大了。再后来GPT-4 Turbo直接拉到128K。OpenAI没公开过具体的训练细节,但业界共识是,GPT-4的预训练主阶段上下文长度大概率不是128K。
那为什么不一开始就用超长上下文训练呢?
一个字,贵。
不对,不是贵,是贵得离谱。
Transformer标准注意力的计算复杂度是O(n²),n是上下文长度。你把上下文从8K拉到128K,长度变成16倍,注意力计算量变成16的平方,256倍。
我知道你可能对256倍没啥概念。这么说吧,假设用8K上下文训练一个大模型需要花1亿美金的算力,那如果你全程用128K来训,在其他条件不变的情况下,光注意力这一块的成本就要乘以256。
当然现实中有FlashAttention、分块注意力、Context Parallelism这些优化手段,不至于真的乘256。但长上下文训练依然贵到令人发指。这也是为什么工业界几乎没有人选择在整个预训练阶段都用超长上下文——那是在烧钱,而且烧得没必要。
因为一个很反直觉的事实是,模型的大部分核心能力,并不需要超长上下文来学。
语言理解、代码生成、逻辑推理、知识记忆、指令跟随……这些能力在8K甚至4K的上下文里就能学得很好。短上下文预训练解决的是模型「会不会思考」的问题。长上下文训练解决的是另一个问题——模型「能不能在读了一本书之后还记得第三页的细节」。
这两件事的性质完全不同。
所以行业里形成了一个被广泛采用的训练范式,我给你翻译成大白话:
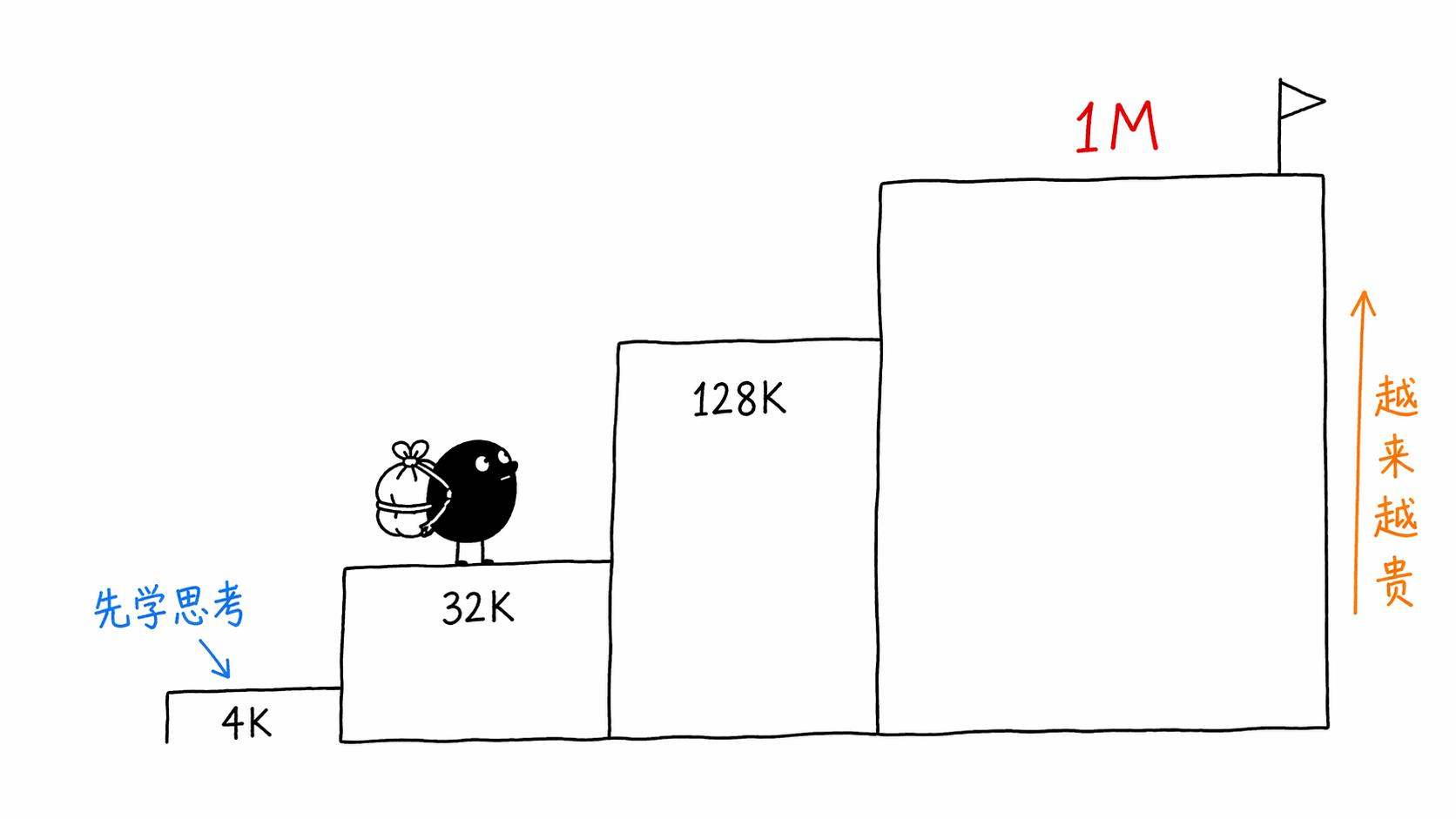
第一步,用短上下文(4K到16K)大规模预训练。这一步花的时间最长、吃的数据最多、烧的钱最多。模型在这个阶段学会了「怎么当一个聪明的AI」。
第二步,用中等上下文(32K到64K)继续训练一段时间。让模型适应更长的位置编码,学会处理更长的文本依赖。
第三步,用长上下文(128K甚至更长)做专项训练。用长文档、长代码仓库、多文档QA这些数据,教模型「怎么在超长输入里工作」。
第四步,指令微调和偏好对齐。教模型在长上下文场景下该怎么回答问题、怎么引用信息、怎么忽略无关内容。
你看,模型的「聪明」是在第一步学的,模型的「长记忆」是在第三步补的。
这里面有个非常关键的技术点,叫位置编码扩展。
Transformer需要知道每个token在序列中的位置。如果训练的时候只见过0到8192的位置,你突然让它处理位置128000的token,它就懵了——这些位置它从来没见过,不知道该怎么处理。
所以行业里发展出了一整套技术来解决这个问题。RoPE Scaling、NTK-Aware Scaling、YaRN、Position Interpolation……2023年一篇叫YaRN的论文证明了一件很牛的事——你可以用比之前少10倍的token和少2.5倍的训练步数来扩展上下文窗口。 这意味着「撑大窗口」这件事变得越来越便宜了。
但是,这里有个但是。
位置编码扩展只是让模型「看得见远处」,不代表它「会用远处的信息」。
就像给一个近视的人配了望远镜,他能看到远处了,但不代表他能从远处那堆杂乱的信息里精确找到他需要的那一条。所以光做位置编码扩展还不够,你还得用长文本数据让模型真正「练习」怎么在远距离上做注意力。
有一篇2024年的研究专门分析了这个问题,他们发现Llama 3.1 70B虽然标称支持128K上下文,但在RULER评测上的有效上下文长度只有64K——刚好是标称的一半。
好,到这里你应该已经理解了第一个核心事实——训练上下文长度和推理上下文长度,是两码事。
但我觉得更有意思的是第二个事实。
回到我们开头的问题。一个模型宣称支持200K上下文,你是不是默认它在200K范围内都一样聪明?
不是的。
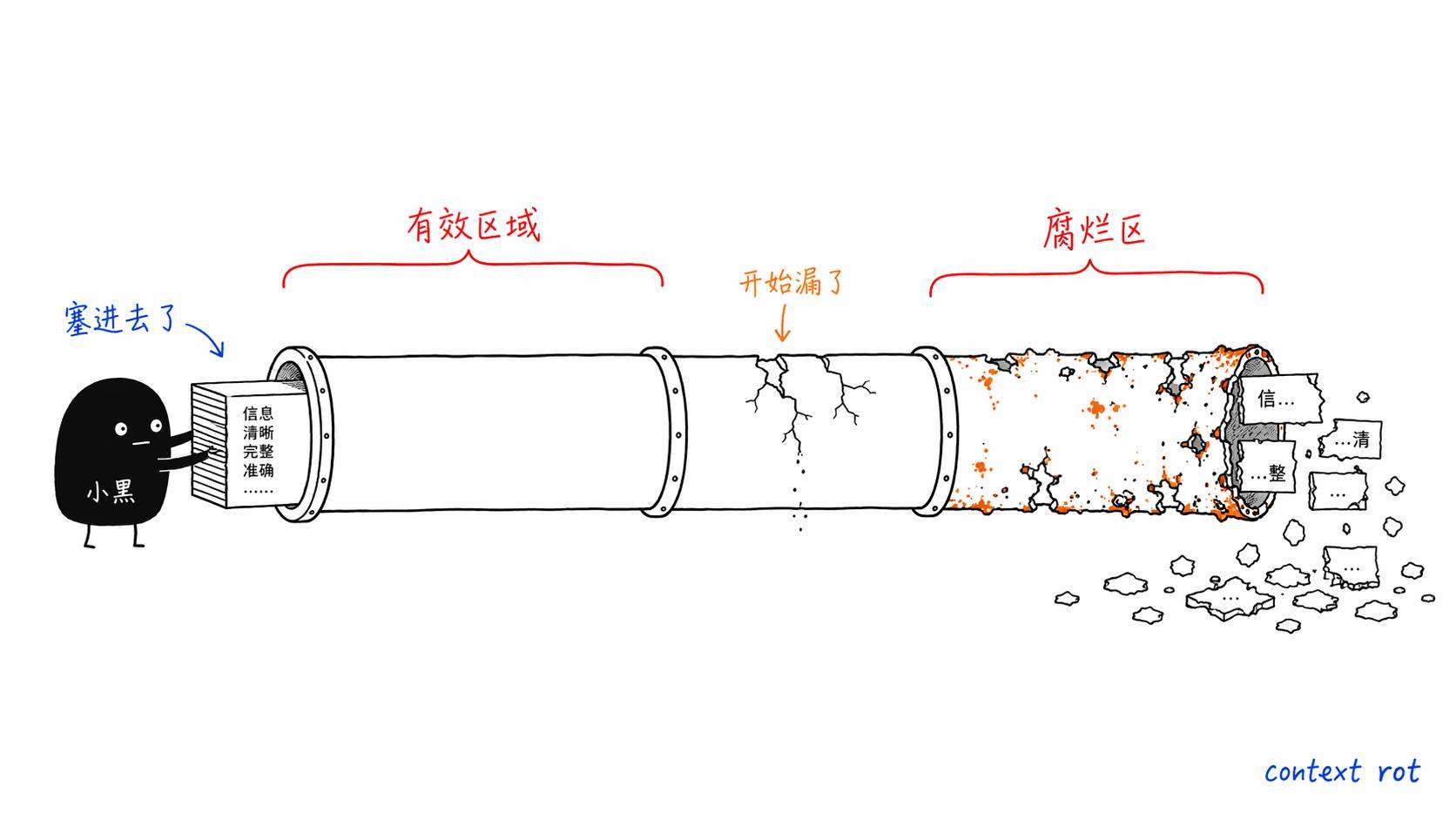
2025年7月,一个叫Chroma的团队发布了一篇研究报告,题目叫「Context Rot」,上下文腐烂。他们测了18个当时最强的前沿模型——GPT-4.1、Claude 4、Gemini 2.5、Qwen3都在里面。
结论让人有点不舒服:所有模型的性能都会随着输入长度增加而下降。所有。没有例外。
而且下降不是均匀的。有些任务在上下文超过50K之后就开始明显退化。有些模型在中间位置(不是开头也不是结尾)的信息检索准确率断崖式下跌。准确率下降幅度可以达到30%到50%,而且远在达到标称上下文上限之前就已经发生了。
这被业界总结成一句话,我觉得每个用AI的人都应该记住:
标称上下文长度 ≠ 有效上下文长度。
2026年初有人做了一个更系统的测试。在NIAH-2(Needle-in-a-Haystack 2.0)评测中,把上下文拉到100万token,各个模型的单针检索准确率分别是,GPT-5.5 96%、Gemini 3 99%、Claude Opus 4.7 89%、DeepSeek V4-Pro 78%。
你注意到了吗?即使是最强的模型,在100万上下文里也做不到100%。而这还只是最简单的「大海捞针」——在一堆文本里找一个明确的事实。如果换成更复杂的任务,比如跨越几十处证据做推理、发现前后矛盾、在大量干扰信息中找隐藏条件,准确率还会进一步下滑。
有一个例外值得单独说,Gemini 1.5 Pro。Google在技术报告里说,Gemini 1.5 Pro从架构设计之初就考虑了超长上下文,用了Mixture-of-Experts架构加上专门的训练基础设施,在100万token甚至1000万token的范围内实现了接近完美的检索能力,next-token prediction loss一直到1000万token都在持续下降。
这是目前唯一一个看起来是「从头为长上下文设计」而不是「后期扩展」的主流模型。 但即便如此,Google也没有公开具体的预训练序列长度到底是多少。
所以你现在可以理解一个更完整的图景了。
模型的上下文能力,其实分三层:
第一层是标称上下文长度——产品页面上写的那个数字,128K、200K、1M。这只是说API接口允许你塞进去这么多token。
第二层是训练上下文长度——模型在训练时真正练习过的最长序列。这个数字通常比标称的要短,可能短很多。
第三层是有效上下文长度——模型在实际任务中真正能可靠利用的范围。这个数字往往比标称的还要短。
三个数字,三个不同的东西。但厂商营销的时候只会告诉你第一个。
顺着上面的再聊聊。这件事为什么让我觉得值得写出来跟大家聊?
因为这是AI领域一个特别典型的「参数营销」案例。上下文长度这个数字,已经变成了模型之间军备竞赛的武器。从8K到32K到128K到200K到1M到10M,数字越来越大,但很少有人告诉你——这些数字背后的含金量是不一样的。
一个用8K预训练然后硬扩到128K的模型,和一个真正在128K长度上做了充分训练的模型,它们的128K是同一个128K吗?
不是。
就像两个人都说自己能跑马拉松。一个人每天训练跑42公里,另一个人每天训练跑5公里但偶尔冲刺一下。他们都能完赛,但你猜哪个在30公里之后还能保持配速?
这也解释了为什么你在实际使用中可能有过这种体验——你给AI塞了一大堆文档,问它一个关于文档中间某处的细节问题,它要么答不上来,要么开始胡编。不是AI故意骗你,是它在那个距离上的注意力确实不够用了。
Chroma的研究把这种现象叫做Context Rot,上下文腐烂。我觉得这个名字起得太好了。
不是说上下文窗口满了才会出问题。是随着你塞进去的内容越多,模型对每一条信息的处理质量就在缓慢地、不均匀地衰减。就像一块铁放在空气里,不是突然断裂,而是一点一点地生锈。
他们发现了几个很有意思的规律:
信息和问题之间的语义相似度越低(也就是答案和周围的文本越不像),模型就越容易在长上下文里把它弄丢。
模型对文本开头和结尾的记忆最好,中间最差。这被称为「位置偏差」。
当文本里存在大量跟答案「长得像但不是」的干扰信息时,模型的表现会急剧下滑。
这些都指向同一个结论——长上下文不是一个你打开就自动好使的功能,它更像是一个需要你理解其特性、主动适配的工具。
我自己现在的使用策略是这样的,我觉得还挺有效的。
如果信息真的很重要,我会把它放在输入的开头或者紧挨着问题的位置。不要把关键内容扔在中间一大堆无关文本里。
如果要让AI处理超长文档,我倾向于先分段处理再综合,而不是一股脑全塞进去祈祷它全都能记住。
如果我在乎准确性,我会明确告诉AI「请引用原文」,这样至少能验证它是不是真的找到了那段信息。
说到底,这件事给我的启发是——在AI领域,你看到的参数和你得到的体验之间,永远存在一层信息差。
标称上下文长度是一个参数。但你真正需要关心的是,在你的任务上、在你的使用方式下、在你塞进去的那些内容的分布下,这个模型到底能不能干活。
这不是AI的错。这是技术发展的客观现实。模型能力的边界不是一条清晰的线,而是一个模糊的梯度带。在这个梯度带里,有些区域它表现得极好,有些区域它开始摇摆,有些区域它就是在装。
知道这条边界在哪,比知道标称数字是多少,有用一万倍。
怎么说呢,我越研究AI的底层逻辑,就越觉得一件事——我们正在经历一个「知道怎么用」比「知道它存在」重要一千倍的时代。
每个人都知道AI能处理超长上下文。但知道它背后的训练逻辑、知道它的能力梯度、知道怎么把关键信息放在它注意力最集中的位置——这才是真正的信息差。
延伸阅读
- Prompt Engineering,用自然语言给AI编程的技术:Prompt Engineering不是那些满天飞的万能模板,而是一种用自然语言给AI编程的能力。五个核心原则、Context Engineering的进化、以及为什么你说话的方式决定了AI能帮你到什么程度。
- 上下文窗口:为什么 AI 会「忘事」:上下文窗口就是AI的工作桌面。从4K到1M,桌子扩大了250倍,但AI真正能「看见」的只有开头和结尾那一小块。这篇文章聊聊Lost in the Middle现象,为什么即便有百万token的窗口,AI还是会忘事,以及你能怎么应对。
- 如何判断一个AI产品是不是在忽悠你:AI行业色素水浓度有点高。四层鉴伪框架教你识别:看技术在哪里、看有没有护城河、看它怎么说话、看它敢不敢让你试。知识不是用来炫耀的,是用来防身的。
- AI Agent,当AI学会自己搞定一整件事:AI Agent是Fine-tuning、Function Calling、MCP三大技术的集大成者。这篇文章从聊天机器人和Agent的本质区别讲起,拆解Agentic Loop的工作机制,坦诚讨论复合错误率的现实挑战,最终回答一个问题:当AI学会独立完成任务,什么能力变得更重要了?
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。