
最近跟一个朋友聊天,他跟我吐槽,说他花了半小时把一整份产品文档喂给 Claude,结果问到最关键的那个接口定义的时候,Claude 一脸无辜地说「我没有看到相关信息」。
他当时原话是,我都塞进去了啊,128K 的上下文窗口我才用了一半,它怎么就看不见呢?
我听完愣了一下,然后跟他说,你知道吗,这个事儿可能跟你想的完全不一样。
上下文窗口大,不代表 AI 真的「看见」了里面所有的东西。
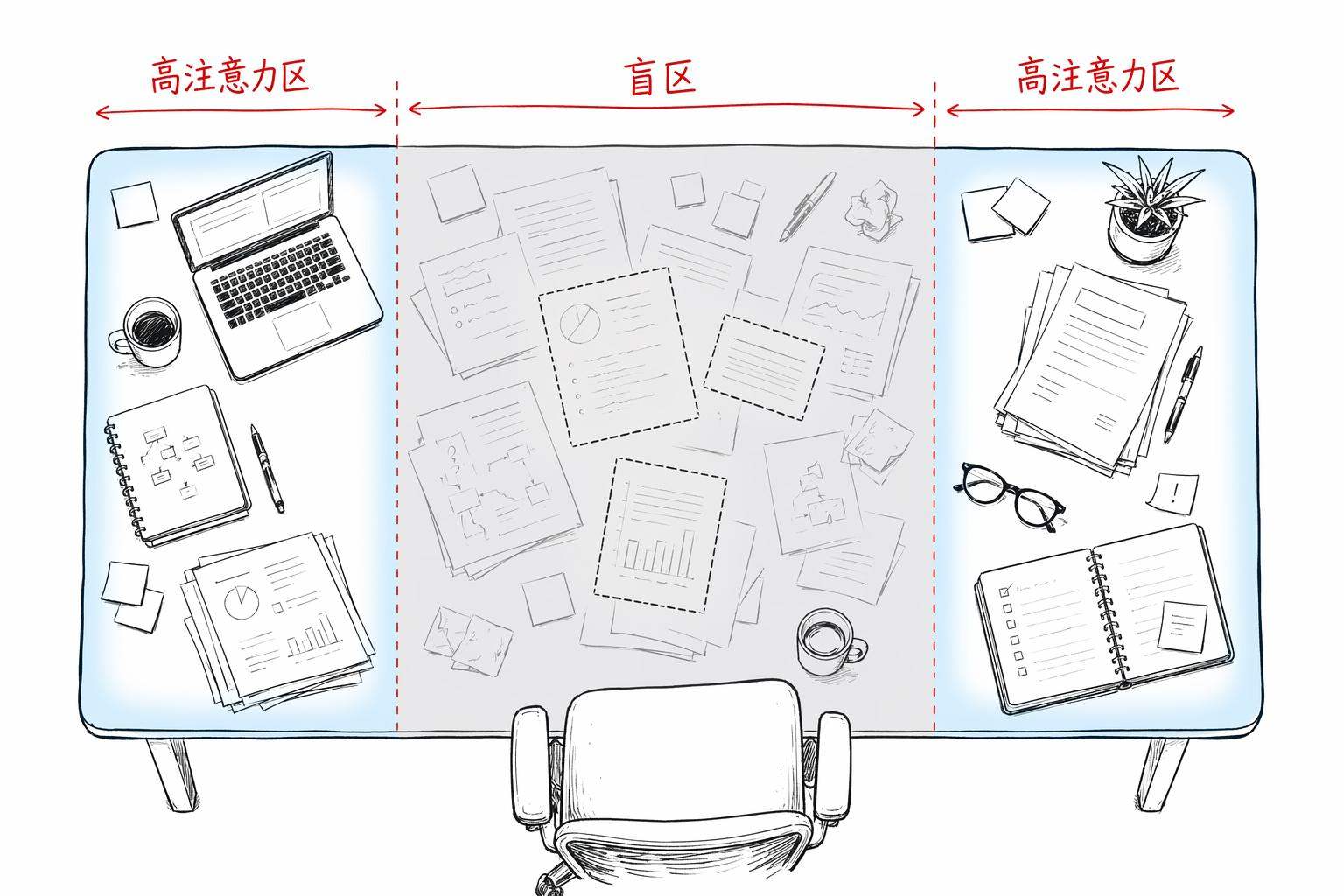
你的工作桌面
我先打个比方。
你想象一下你的工作桌面,就是你面前那张物理的桌子。桌子的面积是固定的,就那么大。你可以往上面堆东西,文件夹、笔记本、手机、水杯、零食。但桌子就那么大,你堆太多东西之后会发生什么?
你找不到东西了。
那份重要的合同明明就在桌上,但它被压在了三本书、两份外卖单和一个快递盒子下面。它在那里吗?在。你能一眼看到它吗?看不到。你得翻。
AI 的上下文窗口,跟你的工作桌面是一回事。
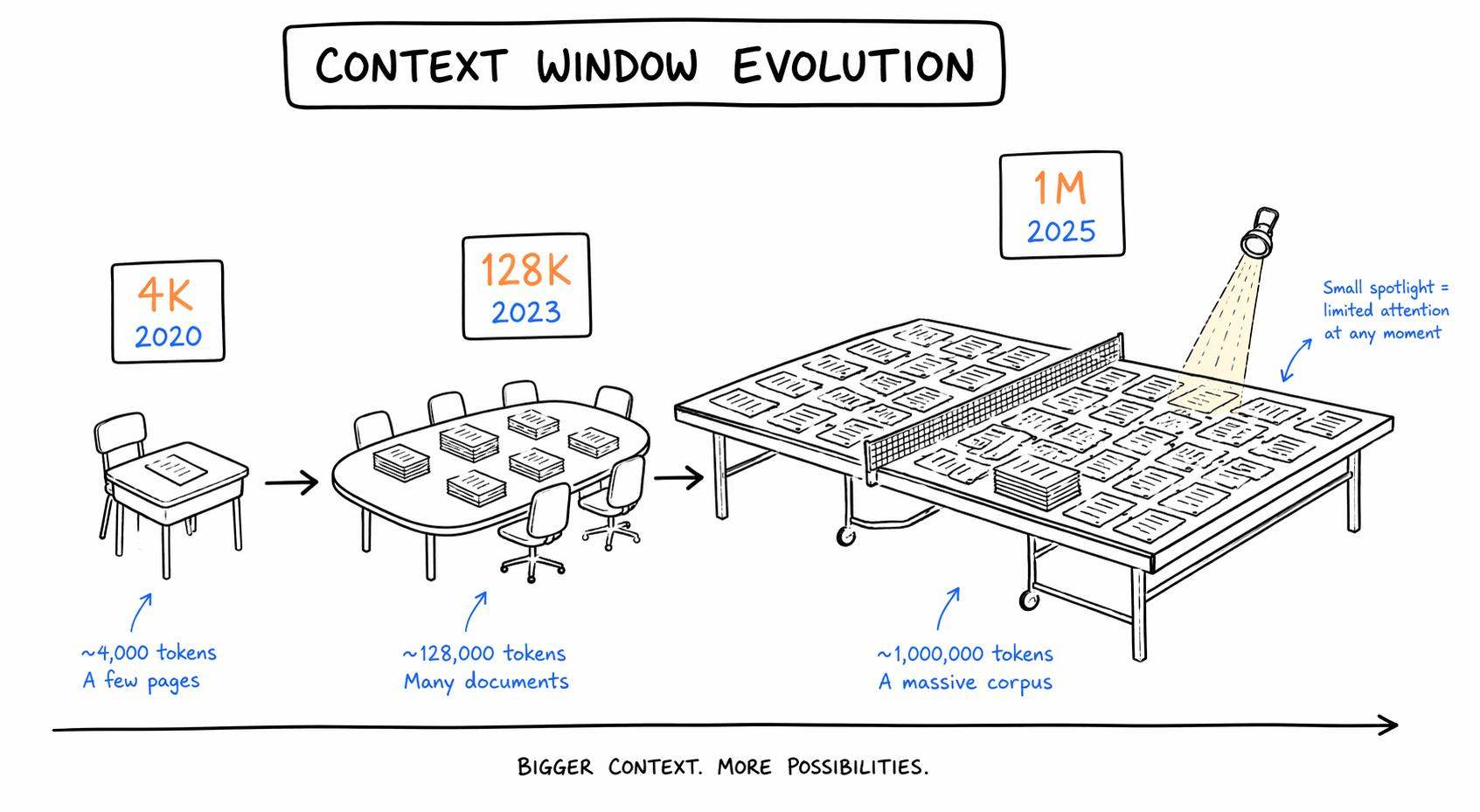
窗口大小决定了这张桌子有多大,4K tokens 是一张小学生课桌,128K 是一张会议长桌,1M 是一张乒乓球台。但不管桌子多大,你真正在看、在用的,永远只是眼前那一小块区域。
桌子变大了,但你的眼睛没有变多。
从课桌到乒乓球台
我们快速过一遍这张桌子是怎么变大的。
2020 年,GPT-3 发布的时候,上下文窗口是 4096 个 token。4K。这是什么概念?大概 3000 字的中文。一篇公众号长文的三分之一。那时候你跟 AI 聊天,聊个五六轮它就开始「失忆」了,因为前面的对话已经被挤出了桌面。
2023 年 3 月,GPT-4 来了,带着 32K 的窗口。同年 Claude 2 直接跳到了 100K。Google 的 Gemini 1.5 Pro 在 2024 年初放出了 1M 的预览。大家突然意识到,哦,原来这个桌子可以无限加大?
到了 2026 年,1M 上下文基本成了标配。Claude Opus 4.6 是 1M,Gemini 3 是 1M,连 Llama 4 Scout 都号称支持 10M。
数字确实在指数级增长。从 4K 到 1M,五年时间翻了 250 倍。
听起来很美对吧?桌子从课桌变成了乒乓球台,理论上你可以把一整本《哈利波特》全七册一口气塞进去,AI 都能装得下。
但这里有一个所有人都在回避的问题。
Lost in the Middle
2023 年,斯坦福和 Meta AI 的研究人员发了一篇论文,标题就三个词,「Lost in the Middle」。
他们做了一个实验。给语言模型塞 20 份文档,其中只有一份包含问题的答案。然后他们把这份「正确答案」的位置不断挪动,放在开头、放在中间、放在结尾,看模型能不能找到。
结果发现了一条 U 型曲线。
答案放在开头,模型能找到。答案放在结尾,模型也能找到。但答案放在中间?准确率断崖式下跌,最高可以跌 30% 以上。
你品一下这件事的荒诞。我都把答案喂给你了,就在你的上下文里,你就是看不见。不是窗口不够大的问题,是你「选择性失明」了。
回到那个桌面的比方,你的桌子确实够大,答案就摆在桌子中间的位置,但你的眼睛天然只盯着桌子的两头。左上角你刚放上去的东西你记得,右下角刚刚翻过的东西你也记得,中间那一堆?。。。模糊了。
这就是所谓的「注意力偏差」,模型对开头有 primacy bias,对结尾有 recency bias,中间就是 AI 的百慕大三角。
有效上下文 ≠ 标称上下文
坦率的讲,这个发现改变了我对大上下文窗口的整个认知。
以前我天真地以为 128K 就是 128K,1M 就是 1M。你给它多少,它就能用多少。后来才发现,标称上下文和有效上下文之间,差着一个太平洋。
Chroma 在 2025 年做了一项测试,把 18 个主流大模型全都拉出来遛了一遍。结论让人有点绝望,每一个模型,我说的是每一个,随着输入长度的增加,输出质量都在持续下降。不是到了某个临界点才突然变差,是从第一个 token 开始就在走下坡路。
RULER benchmark 的结论更直接,大部分号称 128K+ 的模型,在复杂检索任务上的有效上下文,大概只有标称容量的 50% 到 65%。
你买了一张乒乓球台大的桌子,但你真正能用的面积,可能只有一半。剩下那一半,东西放上去了,但你的手够不着,眼睛也看不到。
我自己的感受是,这个比例可能还要更低。我日常用 Claude 处理长文档的时候,真正让我觉得它「全都记住了」的有效区间,大概在 30K 到 50K 这个范围。超过这个量级之后,你就得开始做一件很反直觉的事情,你得帮 AI 整理桌面。
你得帮 AI 整理桌面
说到这个,我觉得还是挺重要的。很多人把大上下文窗口当成了一个「无脑倾倒」的垃圾桶,觉得反正装得下嘛,全塞进去就完事了。
不是这样的。
你想想你自己工作的时候。桌子再大,如果你把所有文件一股脑堆上去不分类不整理,你的效率会变高吗?不会。你会花更多时间在「找东西」上面。
AI 也一样。当你给它一个 100K 的上下文,里面有会议纪要、有代码、有产品文档、有聊天记录,AI 面对的不是一个清晰的任务,而是一坨信息噪音。它的注意力会被分散,会被无关信息干扰,会在中间那片百慕大三角里迷路。
真正会用 AI 的人,不是追求把窗口填满,而是在做减法。
把最关键的信息放在开头,把指令放在结尾,中间的内容保持精简、有结构。这不是什么高深的 Prompt 技巧,就是在帮 AI 整理桌面,让它能一眼看到最重要的那份文件。
有个很实用的操作,如果你有一份超长文档要让 AI 处理,别一口气全塞进去。先让它读一遍然后给你一个摘要,拿着摘要重新组织上下文,把关键信息提到前面,把背景补充放到后面。这一步多花两分钟,但效果差距巨大。
Context Engineering 的时代
顺着上面的再聊聊。
现在行业里有一个新概念在流行,叫 Context Engineering,上下文工程。它说的就是这件事,不是追求更大的窗口,而是研究怎么更聪明地组织你给 AI 的信息。
你想想看,这事儿其实很讽刺。我们花了三年时间把窗口从 4K 扩到了 1M,扩了 250 倍,结果发现问题的核心根本不是大小,而是组织方式。就像你搬进了一间 200 平的大房子,发现收纳做不好的话,住起来还不如原来 60 平的那间小的。
窗口大小是硬件问题,上下文组织是软件问题。硬件已经过剩了,软件才是瓶颈。
MIT 和 Google Cloud AI 在 2024 年发了一篇后续研究,叫「Found in the Middle」,核心发现是这个 U 型注意力偏差其实来源于模型训练时的位置编码机制。他们提出了一些校准方法来缓解这个问题,但坦率的讲,这个问题到今天也没有完全解决。
所以目前最靠谱的办法,还是我们自己来做「上下文工程师」。
这跟你有什么关系
你可能觉得,这些都是技术细节,跟我一个普通用户有什么关系?
关系大了。
你有没有过这种经历。跟 AI 聊了很久,聊到后面突然发现它把你前面说的一个关键要求给忘了。你明明在第三轮对话里说过「用中文回复」,到了第十五轮它突然开始飙英文了。
或者你把一份长长的 brief 丢给它写文章,结果它只抓住了 brief 的开头和结尾的要求,中间那些微妙的限制条件全部被忽略了。
这不是 AI 在偷懒,也不是它「态度不好」。这就是 Lost in the Middle。你的要求被淹没在了上下文的中间地带,AI 的注意力滑过去了。
所以下次你觉得 AI 「忘事」了,不用生气,也不用反复重试。你只需要做一件事,把那个被遗忘的要求,重新放到对话的末尾再强调一遍。
把它从桌子中间那堆杂物里捞出来,放到你眼前最显眼的位置。
这一个小动作,效果立竿见影。
未来呢?
我自己对这件事的判断是这样的。
短期来看,上下文窗口还会继续膨胀。10M、100M 甚至 infinite context,技术路线上都有人在做。但窗口大小这条路,边际收益会越来越低。当 1M 的有效利用率只有 50% 的时候,搞到 10M 又怎么样呢?有效利用率掉到 20%?
真正的突破不会来自更大的桌子,而是来自更聪明的整理方式。
比如让模型学会自己做笔记、自己整理优先级、自己判断哪些信息当前最相关。从被动地接收所有上下文,变成主动地管理和检索。从「更大的 RAM」进化到「带搜索引擎的数据库」。
这个方向上已经有一些有意思的尝试了。RAG 是一种,memory system 是一种,agent 的工具调用也是一种。它们的共同点是,不再试图让模型一次性「看到」所有信息,而是让模型在需要的时候「去找」相关信息。
这跟人类的记忆系统其实是一样的。你的大脑不会同时存着你这辈子所有的记忆,它有一套检索机制,你想到某个线索,相关的记忆才会被激活。AI 最终也会走向这条路。
但那是未来的事了。
现在,你只需要记住一件事。
上下文窗口就是你的工作桌面。桌子再大,你也得整理。否则最重要的那份文件,就会被压在中间,永远不会被看到。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
延伸阅读
- Prompt Engineering,用自然语言给AI编程的技术:Prompt Engineering不是那些满天飞的万能模板,而是一种用自然语言给AI编程的能力。五个核心原则、Context Engineering的进化、以及为什么你说话的方式决定了AI能帮你到什么程度。
- Embedding,AI世界的隐形地基:之前一直知道embedding这个概念但没深入了解过,这次认真研究了一下。从one-hot编码的致命缺陷到Word2Vec的惊人发现,从当前主流模型选型到五大应用场景,用大白话聊透向量嵌入这个AI世界的底层基建。
- RAG,一个让AI学会翻书的技术:之前一直听说过RAG但没有深入了解过,今天花了一整天时间研究,用大白话聊透它的概念、原理、使用场景和最新进展。如果你跟我一样对RAG只停留在听说过的阶段,这篇应该能帮到你。
- Claude Tag 不是重点,重点是所有人都在赌 AI 该住在哪里:Anthropic 发布 Claude Tag,一个住在 Slack 里的 AI 同事。但这不是一个产品新闻,而是一场关于 AI 如何融入工作流的路线之争的最新表态。嵌入派 vs 独立入口派,各家选择的背后是完全不同的生存逻辑。
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。