
别再用 Token 消耗量考核 AI 转型了
最近企业用 AI,已经开始出现一个很现实的问题:工具刚铺开,账单先跑起来了。
Uber 原本按全年规划的 Token 预算,四个月左右就被消耗得差不多了。
亚马逊曾经推动过 AI 使用排行榜,后来又叫停了这类用量排名。
它传递的意思很简单:鼓励大家用 AI 没问题,但把“谁用得多”当成绩单,方向很容易跑偏。
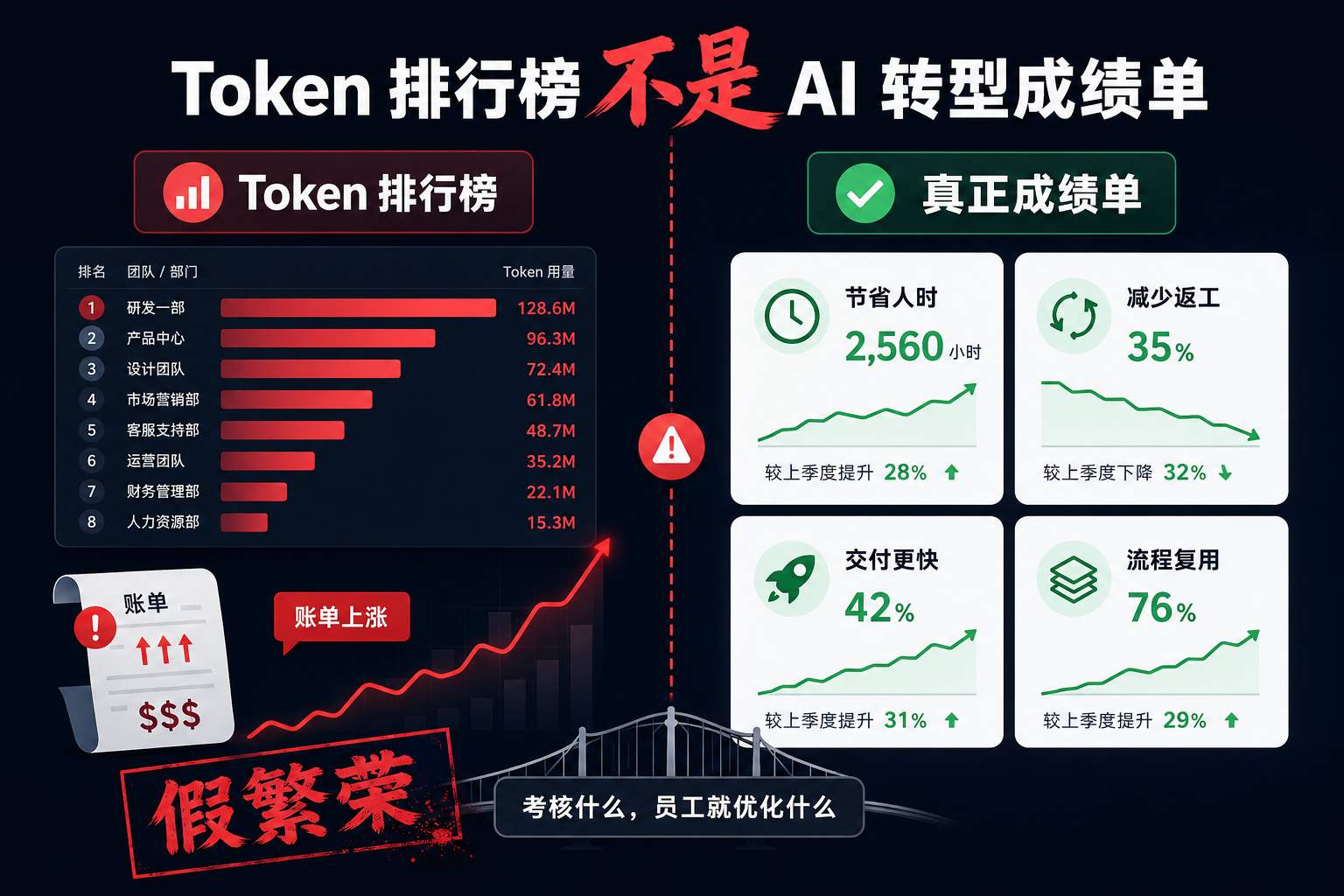
很多公司推 AI,第一反应也是做榜单。
谁用得多,谁排名靠前;哪个部门 Token 消耗高,哪个部门看起来更积极;谁每天问 AI 几十次,好像谁就更拥抱变化。
但这里面有个很大的错觉:Token 消耗量,不等于 AI 转型成绩单。
一句话总结就是:你考核什么,员工就会集中精力干什么。
你考核用量,大家就会想办法把用量做上去。你考核结果,大家才会想办法把流程做对。
用量排名,最容易制造假繁荣
很多团队刚开始上 AI 工具时,确实需要看使用数据。
比如有多少人开通了账号,有多少人试过代码助手,有多少人用 AI 写过文档、做过客服回复、整理过会议纪要。
这些数据有价值,但它们只能说明“有没有开始用”。
一旦把它变成考核,就很容易变味。
员工每天多问 20 次 AI,可能只是把一个问题拆成了 20 轮。部门 Token 消耗翻倍,也可能只是提示词越写越长、资料越塞越多、Agent 在后台反复重试。
看起来热火朝天,账单也很热闹。
问题是,业务结果有没有变好?交付是不是更快了?返工是不是少了?错误率有没有下降?原来 3 个人做 2 天的活,现在能不能 1 个人半天跑完?
Token 本质上是成本单位
Token 本质上是大模型的计费单位之一。
你可以粗略理解成,模型读进去的字、吐出来的字,都会被切成一小段一小段来计算。输入要钱,输出也要钱;上下文越长,账单越容易往上走。
所以问题从来不在于员工用了 AI。
真正的问题是,公司把“用量”直接当成了“价值”。
这就像考核一个销售团队,只看他们打了多少通电话,却不看成交、不看客单价、不看复购。
电话越多,未必生意越好。AI 也是一样。
一个人每天消耗 100 万 Token,可能是在搭一个能复用的自动化流程,也可能是在让模型反复改一份本来 10 分钟能写完的周报。
这两种用法,在账单上都叫 Token。在业务上,完全是两回事。
同样的使用量,账单能差一大截
我们粗略算一笔账。
假设一家公司有 1000 名员工,每人每天 20 次 AI 请求。每次 8000 输入 Token,加 1000 输出 Token。一个月按 22 个工作日算。
总请求量是 44 万次。
按 Claude Sonnet 类价格粗算,一个月大概 17160 美元。
这个数字不算夸张。
但关键在后面:如果 80% 输入命中缓存,月成本大约降到 9557 美元,差不多能省 7603 美元。
这里用的是常见商业模型价格做量级估算,真实成本会随着模型版本、缓存折扣、输出长度和调用方式变化。
这段小账真正想说明的是:同样有 1000 人在用,同样每天 20 次请求,只要上下文复用、缓存、路由、流程设计不同,账单就会差很多。
所以用 Token 消耗量做排行榜,本身就很荒唐。
消耗高,可能代表业务复杂,也可能代表流程粗糙。
消耗低,可能代表没人用,也可能代表工具链设计得更聪明。
单看一个数字,很容易把好事看坏,也容易把坏事看好。
企业真正该看什么
如果我是团队 Leader,我不会把“谁用了多少 Token”放到核心考核里。
我更想看 5 类结果。
- 节省了多少人时
一个原本需要 4 小时的任务,现在稳定缩到 1 小时,这就是结果。
不要只报“用了 AI”。要报节省了哪一步、多少时间、是否可复用。
- 减少了多少返工
AI 介入需求澄清、测试用例、文档检查、客服质检之后,返工率有没有下降?
如果没有下降,说明工具可能只是多了一层热闹。
- 交付速度有没有提高
代码评审、方案初稿、竞品分析、运营素材、数据分析,这些环节有没有更快进入下一步?
速度提升,比使用次数更接近业务价值。
- 错误率有没有下降
AI 很适合做检查清单、边界条件扫描、格式校验、异常提醒。
这些场景不一定消耗很多 Token,但价值很实在。
- 是否沉淀了可复用流程
这是我最看重的一项。
一次好的 AI 实践,不应该只停留在某个员工的聊天记录里。
它应该变成模板、脚本、Agent、工作流、知识库规则,下一次别人也能用。
这才是组织能力。
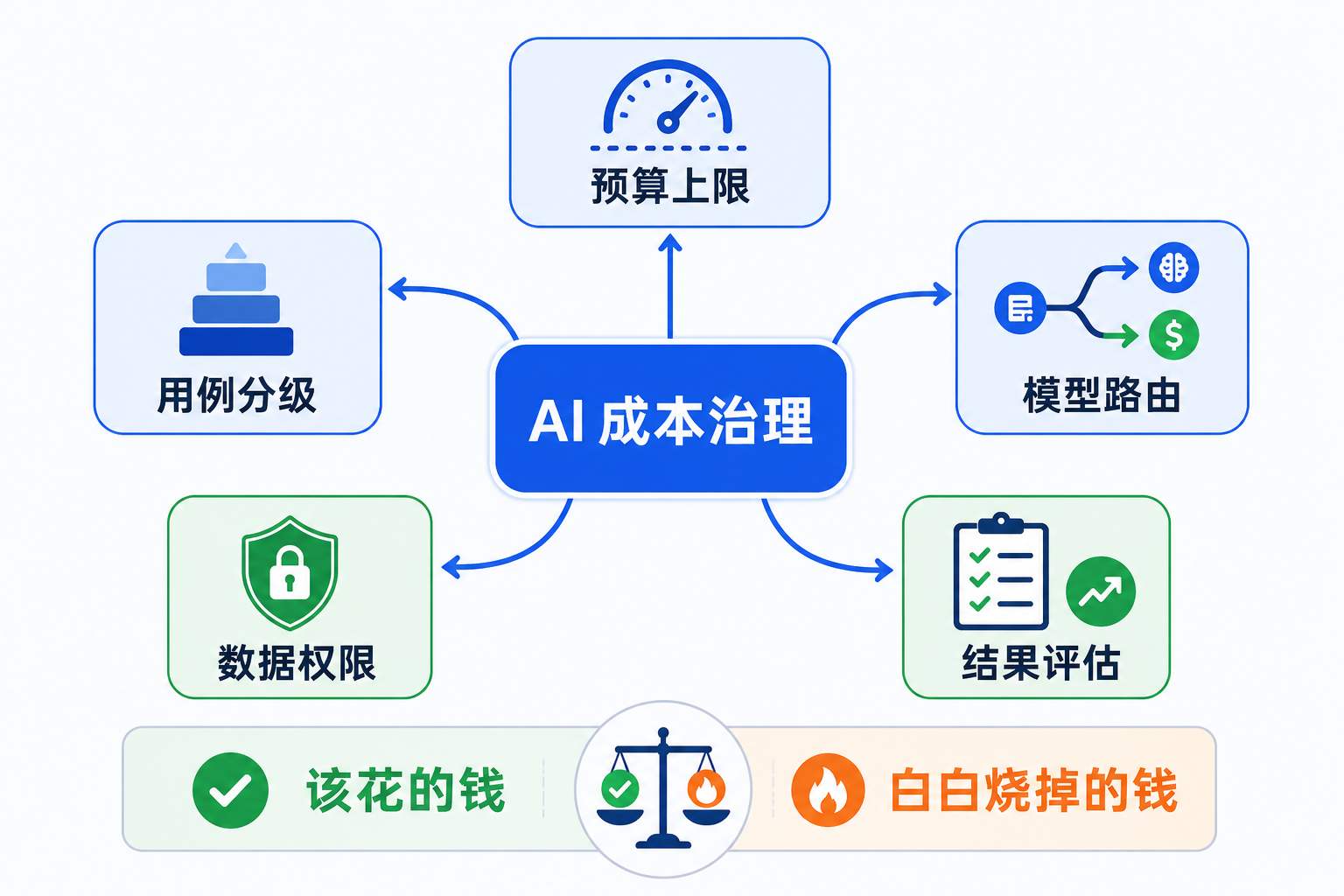
该怎么管 AI 成本
企业 AI 落地,不需要一上来就搞得特别复杂。
但至少要做 5 件事。
- 设置预算上限
每个团队、每类应用、每个 Agent,都要有预算边界。
没有上限的自动化,最后很容易变成账单黑洞。
- 做用例分级
不是所有任务都需要最强模型。
简单分类、格式转换、摘要清洗,可以用便宜模型。复杂推理、关键代码、重要客户回复,再上更强模型。
- 做模型路由
同一个入口背后,可以根据任务类型自动选模型。
员工感知不到复杂度,但公司能把钱花在更该花的位置。
- 管好数据权限
AI 不是一个万能输入框。
什么资料能进模型,什么客户数据不能进,什么文档只能在内网跑,要提前定清楚。
- 做结果评估
每个 AI 项目都要回答一个朴素问题:它到底让哪个指标变好了?
节省时间、减少错误、提升转化、提高交付速度、降低客服等待时长,至少要选一个。
如果一个项目只能证明“大家用了很多”,那它还没证明自己有价值。
第二阶段,比的是用得准
AI 转型第一阶段,企业最怕没人用。
到了第二阶段,真正的风险会变成:大家都在用,但没人知道用得值不值。
这时候再拿 Token 排名、使用次数、活跃人数当核心成绩单,就会把组织带到一个很奇怪的方向。
员工为了排名多问几轮,团队为了数据多接几个场景,管理层看着曲线越来越高,以为转型很成功。
结果可能是:账单上去了,流程没变,交付没快,经验也没沉淀下来。
AI 真正有价值的地方,不是把每个人都变成高频提问者。
它应该把重复工作变少,把关键决策变清楚,把好流程固定下来。
下一阶段,企业真正要比的,是谁能把 AI 用得准、用得稳、用得划算。
我自己做 AI 工具和自动化时,也越来越在意这一点:一个流程如果不能减少等待时间、降低失败率、沉淀成下一次可复用的东西,再热闹也只是成本。
真正能留下来的,一定是结果。
延伸阅读
- 我们给AI出的考试,可能全错了:两份不相干的报告指向同一件事,AI学会了应付考试,而不是真的具备能力。当分数越来越高、可信度越来越低,验证的价值正在超过信任。
- FDE:AI行业给自己开的一张病历诊断书:FDE岗位招聘量一年暴涨729%,这不只是一个新岗位的走红,而是AI行业集体承认了一个事实:模型不是答案,落地才是。
- 孙正义把AI攻击比作机关枪,于是他要卖「补丁即服务」:软银联手OpenAI推出Patching as a Service,把日本前3000家企业的安全防护变成按月收费的订阅服务。当攻击方已经全面AI化,安全正在从一件你拥有的东西,变成一件你租用的东西。
- 给 AI 注入品味:当编码工具性能趋同,审美成了新战场:Emil Kowalski把十年前端经验打包成Skill文件注入AI编码工具、Kimi K2.7成为GitHub Copilot首个开源权重模型、Senior SWE-Bench评估高级工程师任务——当性能不再是瓶颈的时候,品味就成了新的战场。
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。