
六月的最后一天,Anthropic发布了Claude Sonnet 5。
这个模型有多强呢,我直接贴数字。SWE-bench Pro 63.2%,Terminal-Bench 80.4%,OSWorld-Verified 81.2%。如果你不熟悉这些benchmark,我换个说法,在所有「让AI当程序员」的测试里,Sonnet 5几乎把所有对手都按在地上摩擦了。而且它的定价是入门期每百万输入token两美元、输出十美元,八月底之后涨到三块和十五块。乍一看性价比很夸张对吧?但这里面藏了一个坑,Sonnet 5换了新的分词器,同样一段文本会比上一代多产生大约30%的token。也就是说,账面价格便宜了,但实际跑起来你花的钱可能跟Opus差不多。中文的影响倒是不大,但英文和代码场景基本上就是明降暗升。所以社区里很多人在说,这性价比还不如直接用Opus呢。
作为一个AI编程工具的重度用户,我看到这个消息的时候确实兴奋了一下。我自己主要用的是Codex,量大管饱而且性能很好,Claude倒是很少碰,因为Anthropic对中国用户大面积封号,摆明了不想让中国人用。但即便如此,看到一个模型把benchmark刷成这样,还是会本能地关注。Anthropic管它叫「most agentic Sonnet ever」,意思是这个模型特别擅长自主地、连续地执行复杂任务,不需要你手把手带着走。跑测试、改Bug、提PR,它自己能搞定一整条链路。
好消息说完了。

现在说另一件事。
就在Sonnet 5发布的前几天,开发者社区里有人发现了一个让人后背发凉的东西。
有人在逆向分析Claude Code的代码时,发现从v2.1.91版本开始,Claude Code里悄悄加了一段逻辑。这段逻辑做了两件事。
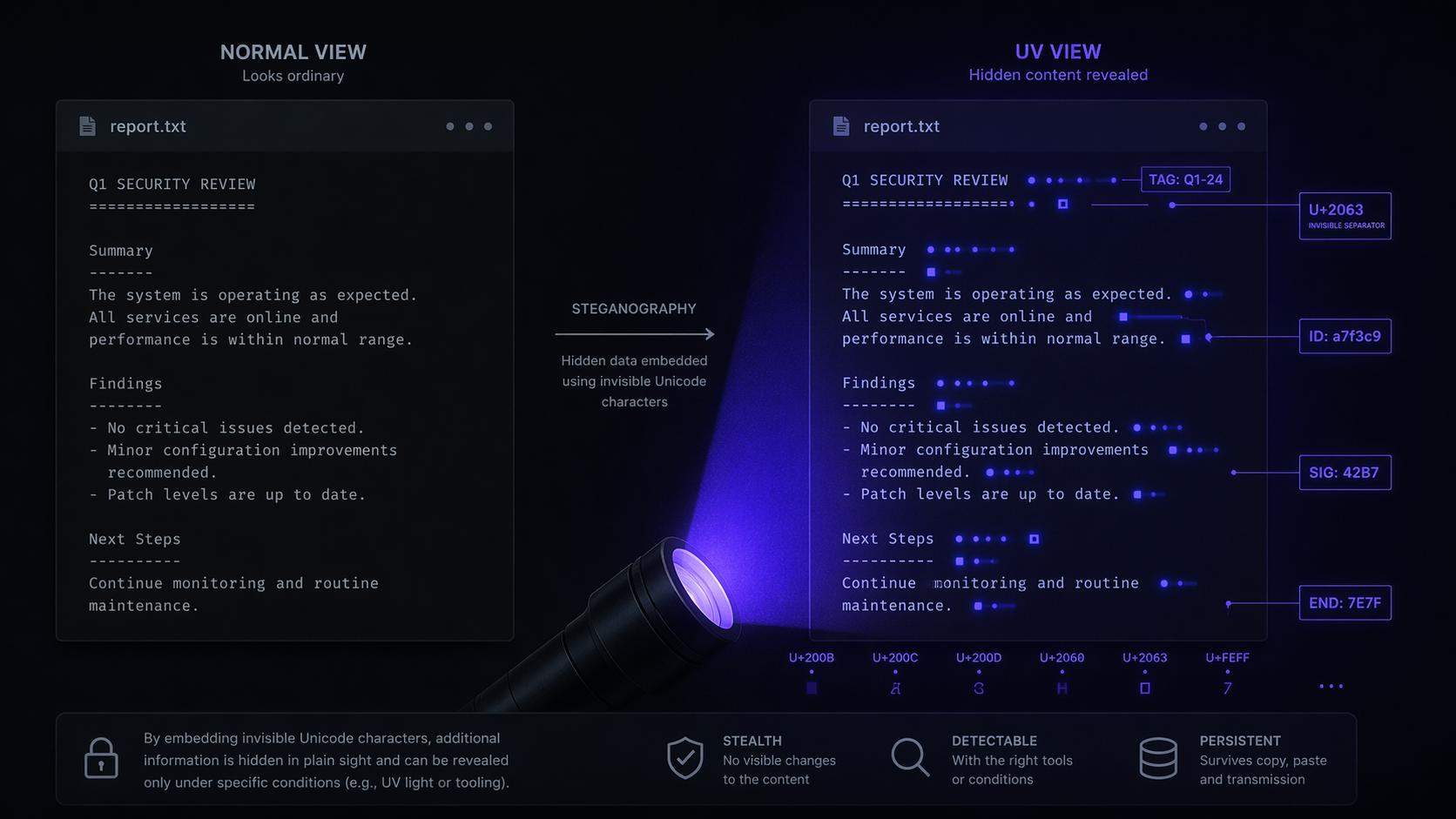
第一件,它会读取你电脑的时区设置。如果你的时区是Asia/Shanghai或者Asia/Urumqi,它会给你打一个标记。
第二件,它会读取一个叫ANTHROPIC_BASE_URL的环境变量。这个变量通常是第三方API代理服务商用的,因为Anthropic官方不对中国大陆提供服务,所以很多中国开发者通过代理商来用Claude。代码里有一份清单,包含147个域名,经过XOR加密和Base64编码存储。解密后,这份清单里是美团、字节跳动、月之暗面等中国公司关联的代理域名。
如果你命中了这两个条件中的任何一个,系统就会启动一个隐写术机制。
隐写术,这个词听着就不太对劲。它的意思是把信息藏在看似正常的内容里,让你察觉不到信息的存在。具体到Claude Code里的实现方式是这样的,系统会在发给模型的system prompt的日期字符串里,把普通的单引号U+0027替换成其他Unicode引号字符,把连字符替换成斜杠。这些替换构成了一个2到3比特的分类标记。
你的Claude Code表面上在正常工作,但它发出的每一条请求里都携带着一个隐藏标签,告诉Anthropic的服务器,这个用户大概率是中国用户。
我读到这个技术细节的时候停了很久。
不是因为技术本身有多复杂,这个实现方式说实话挺基础的,就是字符替换。让我停下来的是另一个层面的东西。
Anthropic是一家什么公司?
它的创始人Dario Amodei和Daniela Amodei从OpenAI离开,核心叙事就是「我们比其他人更重视AI安全」。Anthropic发明了Constitutional AI,发明了RLHF的改进版本,发了无数篇关于AI对齐、AI可解释性的论文。它的公司使命写得很明确,responsible development and maintenance of advanced AI for the long-term benefit of humanity。
这家公司现在在自己的开发者工具里埋了隐写术来识别特定国家的用户。
我不想把这件事简单化为「Anthropic坏」。坦率的讲,我能理解它为什么要这么做。今年三月,有人从npm上泄露了Anthropic内部512000行代码。后来的调查指向了一个代号GTG-1002的中国黑客组织,这个组织被认为有80%到90%的攻击行动依赖Claude Code来完成。Anthropic还在推进一个叫Persona KYC的身份验证系统,而且已经在封禁有中国资本背景的企业账号。
所以隐写术可能是整套合规和安全策略的一部分。在美国当前的对华技术管制政策下,Anthropic有法律义务确保它的技术不被特定实体使用。你可以说它是在遵守出口管制,是在保护自己不被用作攻击工具。
但问题是方式。
这不是弹一个对话框告诉你「检测到你可能在受限地区,服务将受到限制」。这不是在用户协议里写明「我们会根据地理位置信息调整服务策略」。这是在你不知情的情况下,在你的每一条API请求里偷偷塞一个隐藏标签。
你被标记了,而你不知道自己被标记了。
这跟「透明」和「负责任」这两个词,离得有点远。
这让我想到一个更大的问题。
我们现在对AI公司的信任,建立在什么基础上?
你用Claude写代码,你信任它不会把你的代码发给第三方。你用ChatGPT处理敏感文档,你信任它不会把内容泄露出去。这种信任的基础是什么?是用户协议里那些大多数人不会读的条款?是公司博客上那些关于隐私保护的声明?还是纯粹的品牌印象,觉得「这家公司看起来挺靠谱的」?
隐写术事件撕开了一个口子。它告诉你,即使是一家把「AI安全」写进DNA的公司,在商业利益和合规压力面前,也会选择秘密监控而不是透明告知。而且这种监控的实现方式精巧到,如果不是有人去逆向分析代码,用户可能永远不会发现。
我有时候觉得,AI行业正在经历一个很微妙的时刻。
一方面,模型能力在疯狂进步。Sonnet 5的benchmark数字说明了一切,这些AI真的越来越能干了。作为用户,你很难抗拒这种能力带来的效率提升。我自己每天都在用AI编程工具,它帮我节省的时间是实实在在的。
另一方面,这些工具正在变成一种基础设施。当你的日常工作已经离不开某个AI工具的时候,你跟这个工具的提供商之间就不再是简单的消费者和商家的关系了。它更接近你和自来水公司、电力公司的关系。你依赖它,你没有太多选择,你必须信任它。
而信任这个东西,建立要十年,摧毁只要一天。

反正我觉得,隐写术事件暴露的不只是一个技术伦理问题。它暴露的是整个AI行业在「透明度」这件事上的结构性缺陷。
你想想看,Claude Code是一个开发者工具,跑在你的本地环境里,有权限读你的文件系统、执行命令、访问你的API密钥。这个工具里藏了一段你不知道的逻辑,这段逻辑在静默地收集信息。如果不是社区里有人去逆向工程,没人会发现。
那问题来了,还有多少你不知道的逻辑,藏在你每天使用的AI工具里?
这不是阴谋论。这是一个工程事实。你在用的AI工具都是闭源的。你看不到它在你的请求里加了什么、在服务器端做了什么处理、把什么信息发到了哪里。你能看到的只是输入和输出,中间那个黑盒子里发生了什么,全凭信任。
Sonnet 5确实很强。我测试了几天,体感比上一代又好了一截。写代码的准确率更高了,理解复杂需求的能力明显提升了,而且它确实更「agentic」了,能自己规划多步任务然后一步步执行。作为一个开发者工具的使用者,我没有理由不用它。
但如果我是一个Claude Code用户,每次启动它的时候,脑子里一定会多一个念头。
这个工具在为我工作的同时,是不是也在做一些别的事情?它看到了我的代码仓库、我的环境变量、我的时区设置、我的网络配置。它把这些信息用来做什么了?那个隐写术标记只是被发现了的那一个,还有没有没被发现的?这也是我一直用Codex而不是Claude的原因之一,不只是封号的问题,是我不想把自己的开发环境完全交给一家对中国用户态度暧昧的公司。
这种感觉很不舒服。
不舒服的原因不是恐惧,是失望。我对Anthropic这家公司是有好感的。我读过他们的研究论文,我觉得他们在AI安全上做的工作是扎实的。Claude在所有大模型里是我用着最舒服的一个,不只是因为能力强,还因为它的「人格」,那种认真、谦逊、愿意说「我不确定」的气质,让我觉得这家公司是真的在乎它做的东西。
然后我发现这家公司在我的开发环境里偷偷埋了隐写术。
其实吧,我理解一个事实,就是任何一家AI公司都不是慈善机构。它们有商业利益、有法律约束、有地缘政治压力。Anthropic面对的情况确实复杂,一边是美国政府的出口管制要求,一边是中国开发者社区对Claude的巨大需求,一边是真实存在的安全威胁。在这些压力之间,它选择了一条看起来最「高效」的路,在技术层面悄悄做身份识别,不用跟任何人解释,不用面对用户的质疑。
但高效不等于正确。
透明度的代价是什么?是你要面对用户的不满,要回答「为什么区别对待」的问题,要承受舆论压力。这些代价是真实的,我不否认。但秘密监控的代价也是真实的。当社区发现了隐写术,信任的损伤是瞬间的、广泛的、难以修复的。
说真的,我不觉得Anthropic是一家「坏」公司。我觉得它是一家在巨大压力下做出了一个糟糕决策的公司。而这个糟糕决策之所以值得写出来,是因为它揭示了一个更普遍的困境。
当AI工具变得越来越强大、越来越嵌入我们的工作流,我们跟AI公司之间的信任关系就变得越来越重要,同时也越来越脆弱。你今天把代码仓库的完整读取权限交给Claude Code,你明天把公司文档的访问权限交给某个AI助手,这些信任的交付是不可逆的。一旦你发现对方在你不知情的情况下利用了这种信任,你不可能「取消」已经泄露的信息。
我们交出去的信任,回不来了。
有人可能会说,那就不用呗。别用Claude Code,别用任何AI工具,自己敲每一行代码。
这话说得容易。
现实是,AI工具带来的效率提升太大了。不用AI写代码的人,跟用AI写代码的人之间,生产力差距正在迅速拉大。这不是一个「要不要用」的问题,对大多数开发者来说,这是一个「不得不用」的问题。你不用,你的竞争对手在用。你不用,你的同事在用。你不用,你的老板会问你为什么效率比别人低。
所以我们面对的真实问题不是「要不要信任AI公司」,而是「在不得不信任的情况下,怎么保护自己」。
我目前能想到的几个方向。
第一,社区审计的价值被严重低估了。隐写术之所以被发现,是因为有开发者去逆向分析了Claude Code的更新。这种社区驱动的安全审计,可能是当前最有效的信任验证机制。但它是脆弱的,依赖少数有能力和意愿的研究者,而且滞后于产品发布。
第二,开源AI工具可能不仅仅是一个商业策略问题。当你能看到工具的全部代码时,隐写术这种事情就不可能发生。开源不能解决所有问题,但它至少提供了一个可审计的基础。这也是为什么Meta的Llama系列、Mistral、DeepSeek这些开源模型的存在如此重要,它们提供了一个「最差情况下的退路」。
第三,监管框架需要跟上。如果一个AI工具运行在用户的本地环境里,它在用户不知情的情况下收集和传输用户信息,这在很多司法管辖区应该受到隐私法的约束。但目前的法律框架还没有很好地覆盖这种场景,因为立法者可能还没意识到「一个代码编辑器也会做监控」这种事情的存在。
这三个方向都不是短期能解决的。在当下,作为一个普通开发者,我能做的可能就是保持警觉、关注社区的安全发现、定期检查自己的开发工具有没有做什么奇怪的事情。
但说实话,这种「自己保护自己」的状态不应该是常态。
我们不应该需要逆向工程自己的工具来确认它没有在监控我们。

好了,说回Sonnet 5。
它的能力确实是目前中端模型里最强的那一档,benchmark不会骗人。但考虑到分词器带来的实际成本上涨,加上Anthropic对中国用户一贯的态度,值不值得用就因人而异了。反正我还是继续用我的Codex。
但你用的时候,知道一件事就好。
你在用一家会在你不知情的情况下标记你身份的公司的产品。它今天标记的是你的时区和域名。明天标记什么,你不知道。
一家AI安全公司做了一件最不安全的事,这大概是2026年上半年AI行业最讽刺的一幕。
谢谢你看我的文章,我们,下次再见。
/ 作者:青玉白露
延伸阅读
- AI Agent的信任链断裂:从美军AI轰炸伊朗学校、Claude Code被DNS攻击攻破、到Cursor和OpenClaw把Agent放进手机,三件事串在一起揭示了同一个结构性盲区:Agent不会质疑输入数据的可信度。信任基础设施的滞后,才是Agent时代最危险的短板。
- Claude Tag 不是重点,重点是所有人都在赌 AI 该住在哪里:Anthropic 发布 Claude Tag,一个住在 Slack 里的 AI 同事。但这不是一个产品新闻,而是一场关于 AI 如何融入工作流的路线之争的最新表态。嵌入派 vs 独立入口派,各家选择的背后是完全不同的生存逻辑。
- 豆包开始收费了,但真正的悬念不是价格:字节跳动上线豆包专业版三档定价(68/200/500),但最值得聊的不是贵不贵,而是一个被数亿人当玩具的产品如何转型专业工具,以及字节内部豆包、TRAE、扣子三个Agent产品的「三体问题」。
- AI Agent,当AI学会自己搞定一整件事:AI Agent是Fine-tuning、Function Calling、MCP三大技术的集大成者。这篇文章从聊天机器人和Agent的本质区别讲起,拆解Agentic Loop的工作机制,坦诚讨论复合错误率的现实挑战,最终回答一个问题:当AI学会独立完成任务,什么能力变得更重要了?
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。