
一句话总结:输入 Token 主要花在“批量读”,输出 Token 主要花在“逐个写”,Cache hit 则是“前面算过的别再算”。
同样调一次大模型 API,你经常会在账单里看到三行名字:输入 Token、输出 Token、Cache hit(缓存命中)。
很多人第一次看到这里,都会有点别扭。明明都叫 Token,为什么输出更贵,Cache hit 却便宜得像单独开了折扣?
这不是厂商故弄玄虚。它们对应的,其实是三种完全不同的计算活。
KV Cache 也没那么玄。它本质上就是:前面已经算过的上下文先存起来,后面别重算。把这件事想明白,再看定价就顺了。

先把账单翻译成人话
| 账单项 | 模型此刻在做什么 | 并行性 | 主要成本 | 为什么价格常常不同 |
|---|---|---|---|---|
| 输入 Token | prefill:把整段上下文一次读进去 | 高 | 计算吞吐 | GPU 能批量吃,通常更便宜 |
| 输出 Token | decode:一个一个往后生成 | 低 | 串行等待 | 每一步都得等上一步,通常更贵 |
| Cache hit | 复用已有 KV Cache | 很高 | 显存占用、缓存管理 | 跳过大量重复计算,所以更便宜 |
如果你更喜欢一句大白话,可以直接记成这样:
- 输入 Token:整段“读”
- 输出 Token:逐个“写”
- Cache hit:旧内容直接“拿来用”
输入 Token 为什么通常便宜,输出 Token 为什么通常更贵
模型处理输入的时候,最像在看一整页文档。
你一次给它 1000 个 Token,它会尽量把这 1000 个 Token 一起过一遍。这一步叫 prefill。对 GPU 来说,这类活很舒服,因为它适合铺开算,吞吐高,机器不会老在等。
所以输入 Token 的关键,不是“字多不多”,而是“这批字能不能一起算”。
输出就不一样了。
模型生成回答,不是把整段话一次写完,而是先生成下一个 Token,再拿着它继续生成下一个。你可以把它理解成一边写,一边回头看自己刚写的内容。第 37 个 Token 没出来,第 38 个 Token 根本没法算。
这一步叫 decode。
decode 最大的问题,不是算不动,而是没法像 prefill 那样舒服地并行。每往后吐一个 Token,整条链路都要再走一次,只不过这次只服务这一个新 Token。
所以很多模型里,输出 Token 的单价会比输入 Token 更高。不是它“更高级”,而是它更吃串行等待。
KV Cache 到底省掉了什么
如果每次生成新 Token,都要把前面的上下文完整重算一遍,聊天类产品的成本会高得很难看。
KV Cache 就是拿来解决这个问题的。
它做的事情很朴素:前面那些已经算过、而且不会变的中间结果,先留在显存里。下一个 Token 来的时候,只算新增部分,再去读取前面缓存好的 Key 和 Value。
所以 KV Cache 本质上不是“让模型更聪明”,而是“让模型别重复劳动”。
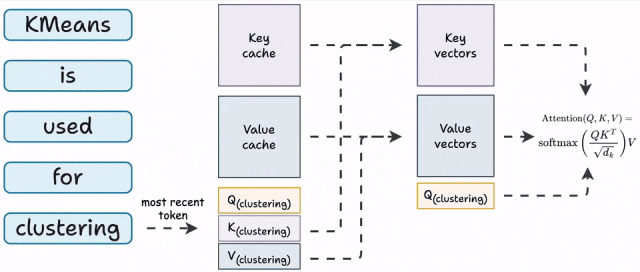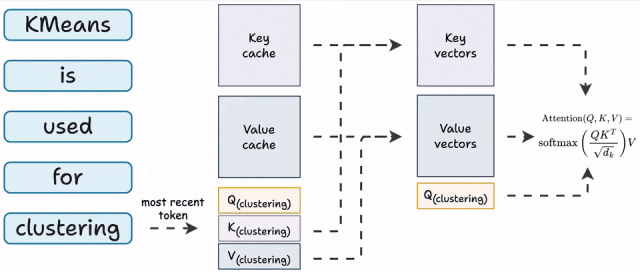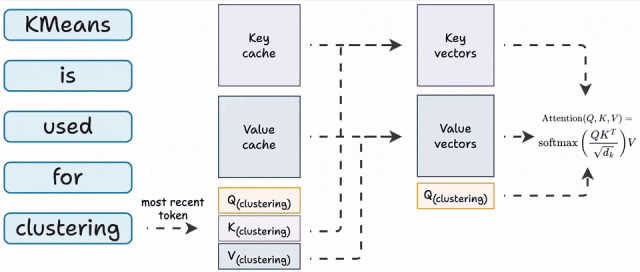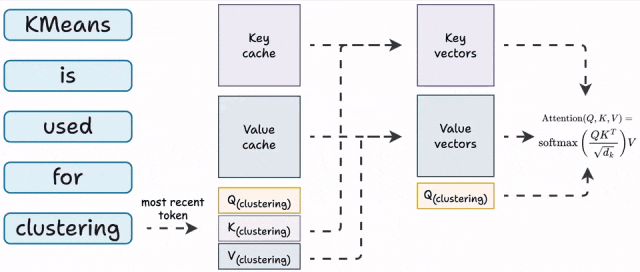
这也解释了两个很常见的现象。
第一,首字延迟通常更高。
因为模型得先把整段输入跑完,把 KV Cache 热起来。你 prompt 越长,这一下就越慢。
第二,Cache hit 往往特别便宜。
因为命中缓存时,服务端并不是“少算一点”,而是把一大段本来要做的 prefill 直接跳过去了。你看到的低价,本质上是重复计算被省掉了。
但便宜不等于没有代价。
KV Cache 很吃显存。上下文越长、并发越高,需要留住的缓存就越多。也正因为这样,厂商才会把“复用缓存”单独拿出来计费:它虽然省了大量算力,但仍然占着很贵的工作内存。
一个最小例子,看 Cache hit 怎么影响账单
假设你在做一个固定前缀很长的应用,比如客服机器人,或者 OpenClaw 这种 Agent。
它每次请求前都要带上一大段 system prompt、工具说明和项目背景。
第一次请求可能是这样:
system prompt: 2000 输入 Token
user message: 50 输入 Token
model answer: 300 输出 Token
这一次里,前 2050 个 Token 都要完整做 prefill,同时把可复用的 KV Cache 建起来。
第二次请求,如果前缀基本没变,账单就会更像这样:
system prompt: 2000 Cache hit
user message: 40 输入 Token
model answer: 220 输出 Token
差别就在这里。
那 2000 个已经算过的前缀,没有再按普通输入 Token 重新计费,而是以 Cache hit 的方式复用。真正重新计算的,只剩新进来的 40 个输入 Token,以及后面生成的 220 个输出 Token。
所以你看到 Cache hit 便宜,不是平台突然良心发现,而是这部分计算本来就被跳过去了。
看账单时,你到底该盯哪一项
如果你只是偶尔调一下模型,账单里三项都不大,感受不会特别强。
可一旦进入长对话、Agent、长文档处理这几类场景,差别就会很明显。你可以这样看:
-
前缀很长,而且会反复复用
重点看 Cache hit。系统提示词、知识库前缀、工具说明越固定,缓存命中率越关键。 -
每次都塞大量新资料进去
重点看输入 Token。长文档问答、批量分析、RAG 拼接过长时,这里最容易涨。 -
模型特别爱说,或者你要求长输出
重点看输出 Token。摘要、写作、代码解释这类任务,输出成本常常比你想得更重。 -
首字很慢,但后续输出还行
大概率是 prefill 太重,不一定是网络问题。先看前缀是不是太长,再看缓存有没有命中。
一句话总结就是:不要把 Token 当成一个总数看,要把它拆成“读了多少、写了多少、复用了多少”。
你真的这样拆开看,很多“为什么这次这么贵”的问题,基本当场就能定位。
延伸阅读
- AI公司正在失去定义自己边界的能力:OpenAI主动送5%股权,Anthropic被五角大楼逼拆护栏。看似截然不同的选择,底层逻辑一样:AI公司的独立性窗口正在关闭。互联网公司走了二十年的路,AI只用了四年。
- AI的账单到了:花旗限制旗舰模型、扎克伯格承认Agent不如预期、谷歌用电量超新西兰——三条新闻串起同一个转折:从不计代价追求能力到在成本约束下找最优解。免费午餐阶段结束了。
- 给 AI 注入品味:当编码工具性能趋同,审美成了新战场:Emil Kowalski把十年前端经验打包成Skill文件注入AI编码工具、Kimi K2.7成为GitHub Copilot首个开源权重模型、Senior SWE-Bench评估高级工程师任务——当性能不再是瓶颈的时候,品味就成了新的战场。
- Agent 嵌入一切:从支付宝到群聊,AI 正在吞噬 App:支付宝阿宝开放公测、Skywork Tags让Agent加入工作群聊、千问Agent工程方法论——三件事串在一起看,2026下半年Agent的主旋律已经很清楚了:Agent的终局不是做一个新App,而是消失在你已有的工作流和生活流里。
评论区
欢迎留下你的看法,支持匿名评论。
你的评论会公开展示,建议填写便于交流的昵称,并尽量提供有信息量的反馈。